Appearance
数据处理
数据集 可以包含来自不同来源的数据,这些数据被整合、清洗、转换,最终输出为一张数据集合(数据表),以便于进行查询和分析。
场景代入 有助于了解数据集!
在了解数据集功能之前,我们先进入一个场景
场景:1栋办公楼、4层、每层有5个房间,每个房间有1块电表分别计量总的电量
需求:我们需要统计出每个房间、每层楼、整栋楼的耗电量以及对应的电费,然后按照日报、周报、月报、季报进行统计
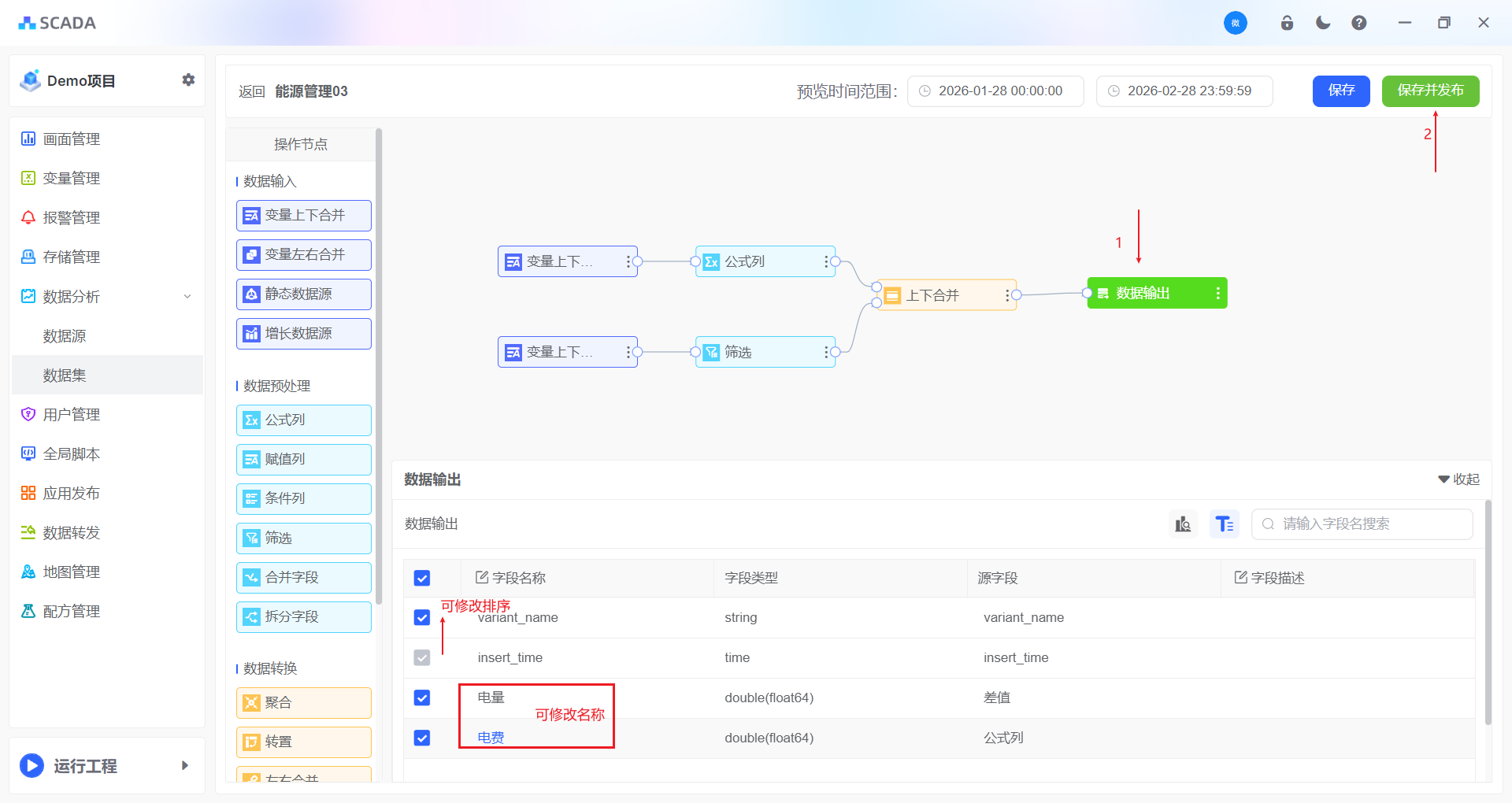
实现步骤:
- 变量存储,按照每小时存储1条记录,存储的数据为电量累计值。内部存储规则为:1个变量1张数据库表
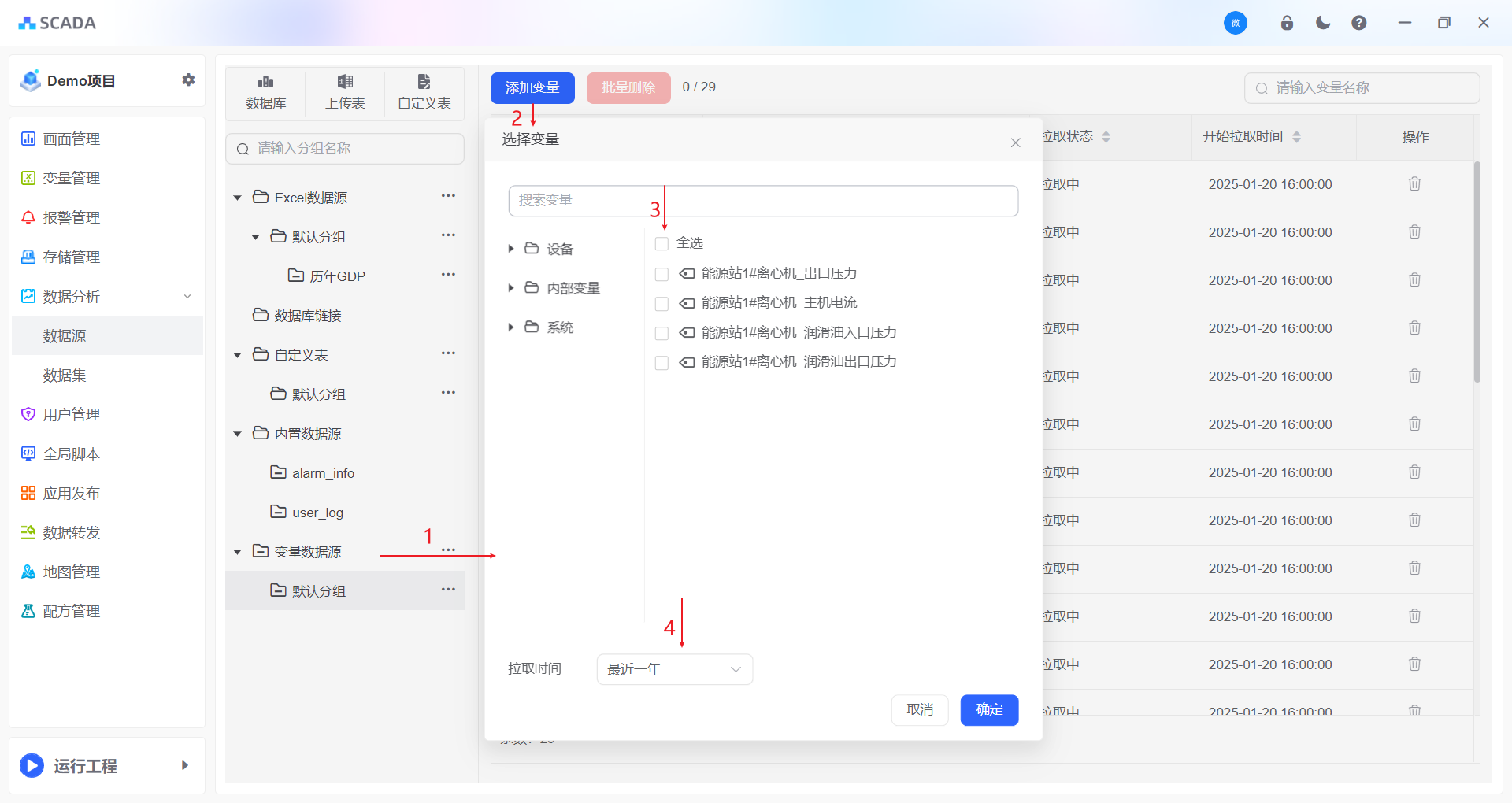
数据分析-示例-添加变量
- 在数据集中对数据进行电能统计、楼层分类、房间分类、电费计算,形成一张完整的数据表
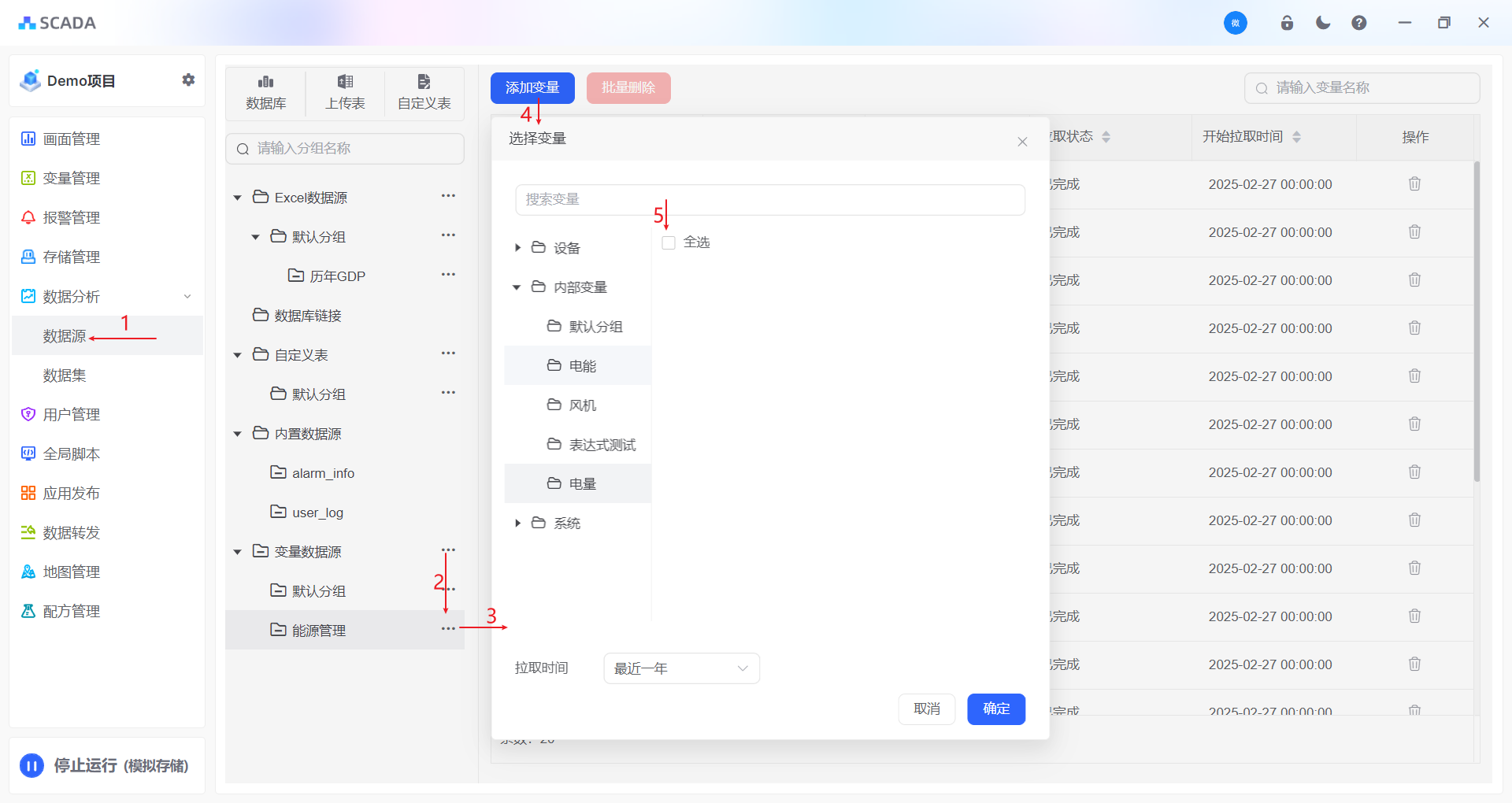
- 将需要分析的数据添加至
数据源
- 创建数据集-->在数据集中将存储的20个变量合并到一张表
选择差值,自动计算每个小时的差值,计算规则举例:13点的电能用量=14:00值-13:00值
将数据标记对应的楼层、对应的房间,根据变量的名称通过分隔符进行字段拆分
计算每个小时的电能费用
- 输出最终的表
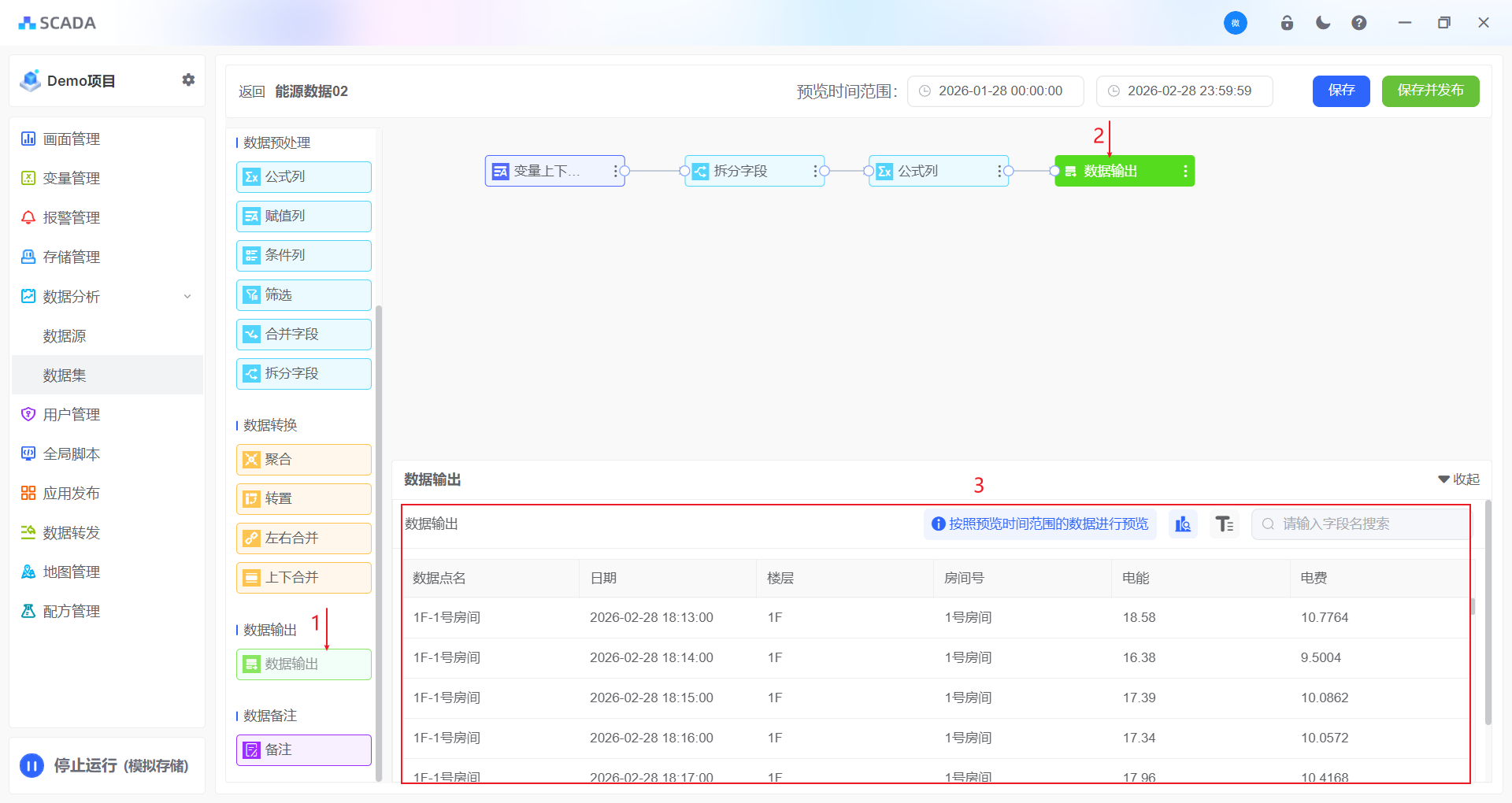
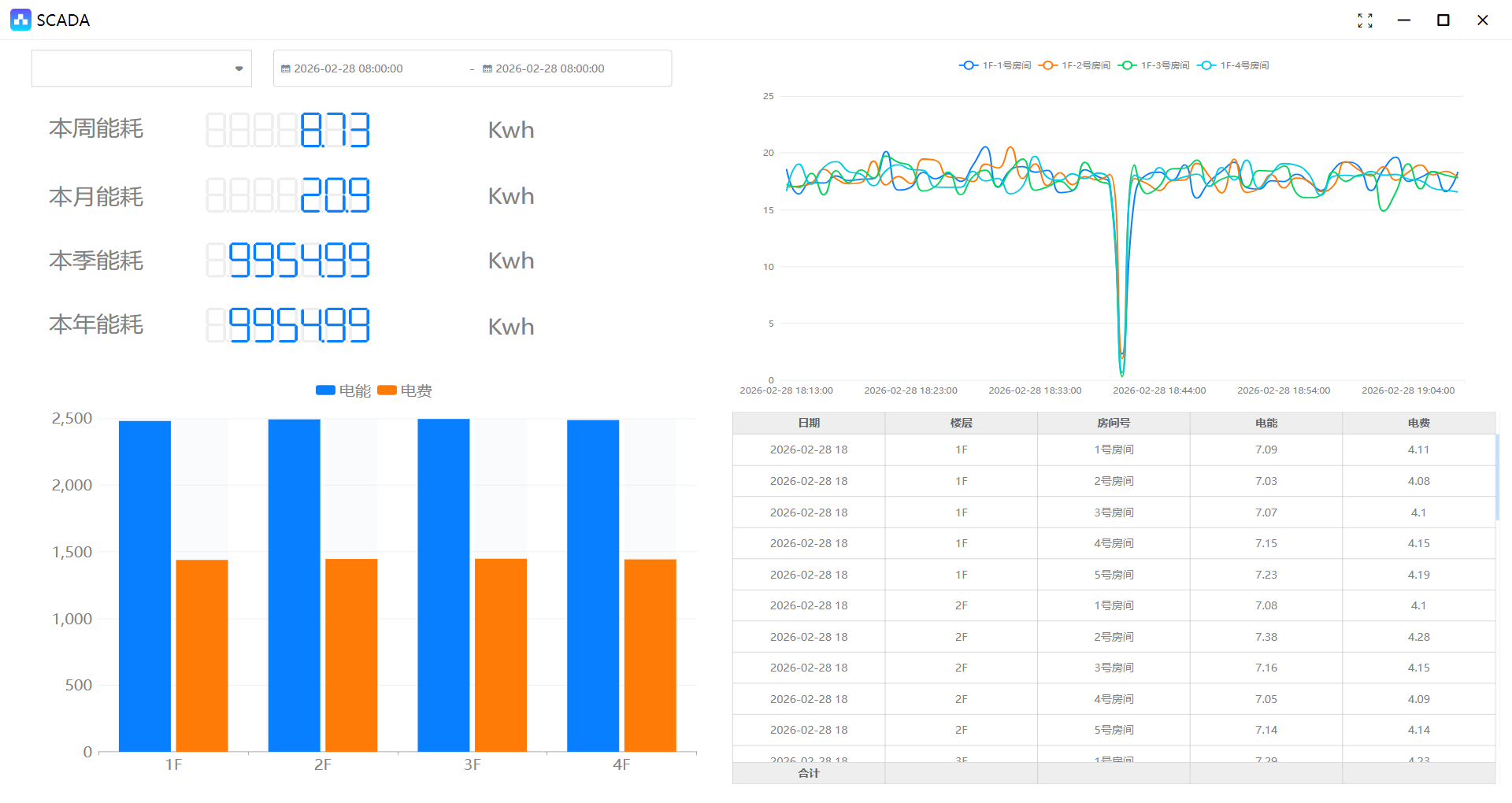
3、在画面编辑器中对数据集中生成的表进行展示
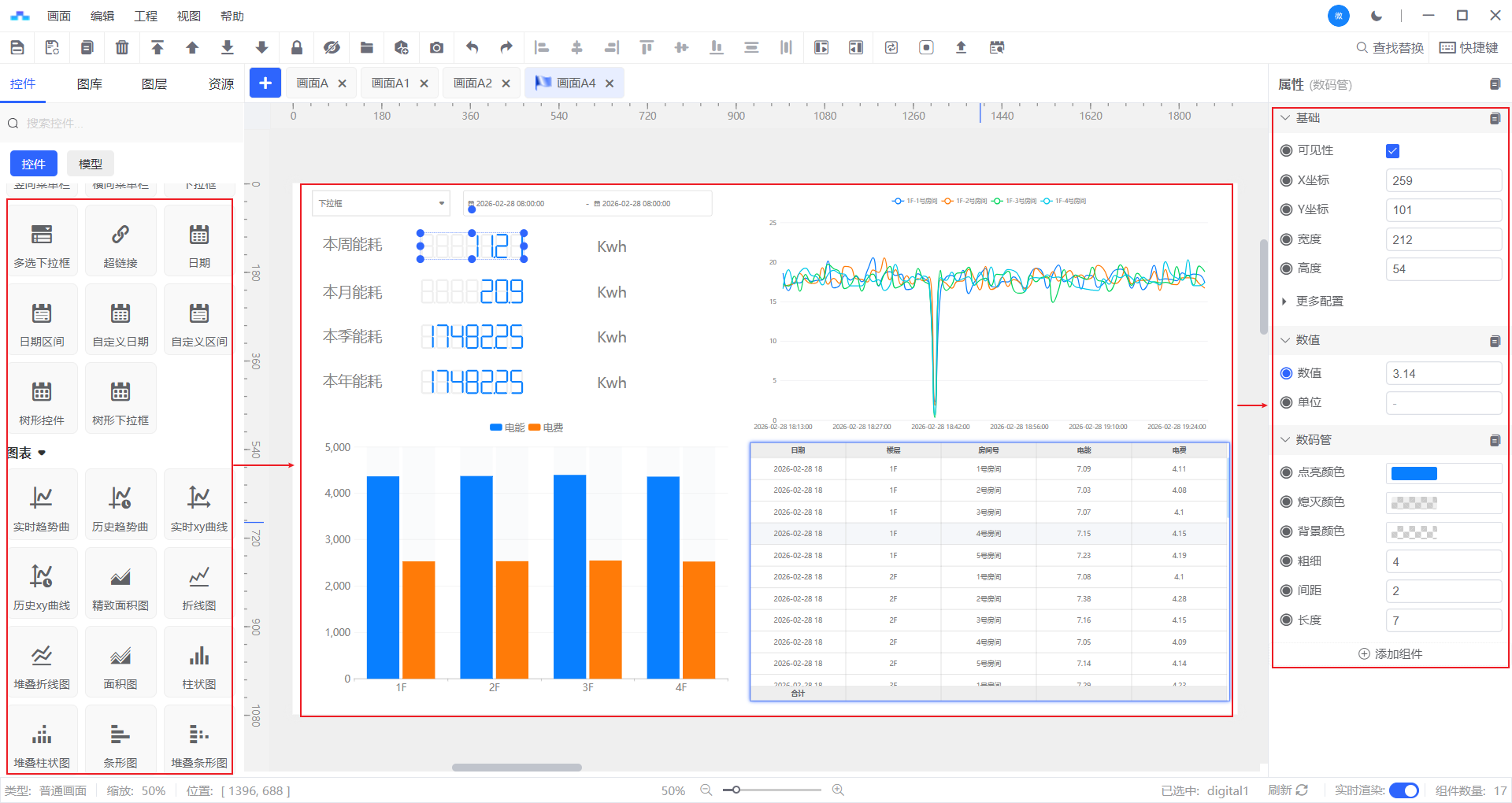
总结: 以上过程我们会发现数据的处理全部都在数据集中完成,从变量的选择、差值的计算、数据的标记、电费的计算等等操作,操作完成之后,输出了一张最终的表格,在画面编辑器中展示的所有数据来源都是这张表格。
添加变量
系统中,用户可将已存储的、需参与数据分析的变量添加至数据源。添加完成后,系统将自动从时序数据库中拉取对应变量的历史数据,并将其写入系统内置的关系型数据库。
数据拉取策略如下:
时间粒度(聚合周期): 支持以下8种预设时间间隔,每个间隔将自动生成一张独立的宽表:
1分钟、5分钟、10分钟、30分钟、1小时、12小时、1天。
聚合指标类型: 针对每个时间窗口内的原始时序数据,系统将自动计算并存储以下9类统计值:
最大值(Max)、最小值(Min)、起始值(First)、结束值(Last)、平均值(Average)、数据条数(Count)、总和(Sum)、差值(Last − First)、分组后总数量(Group Count,用于多变量联合分析场景)
提示
数据拉取的时长会根据实时数据库中所选变量的数据量大小动态调整:数据量越大,拉取所需时间越长。拉取任务完成后,系统将自动更新状态,并在界面上显示为“已完成”。
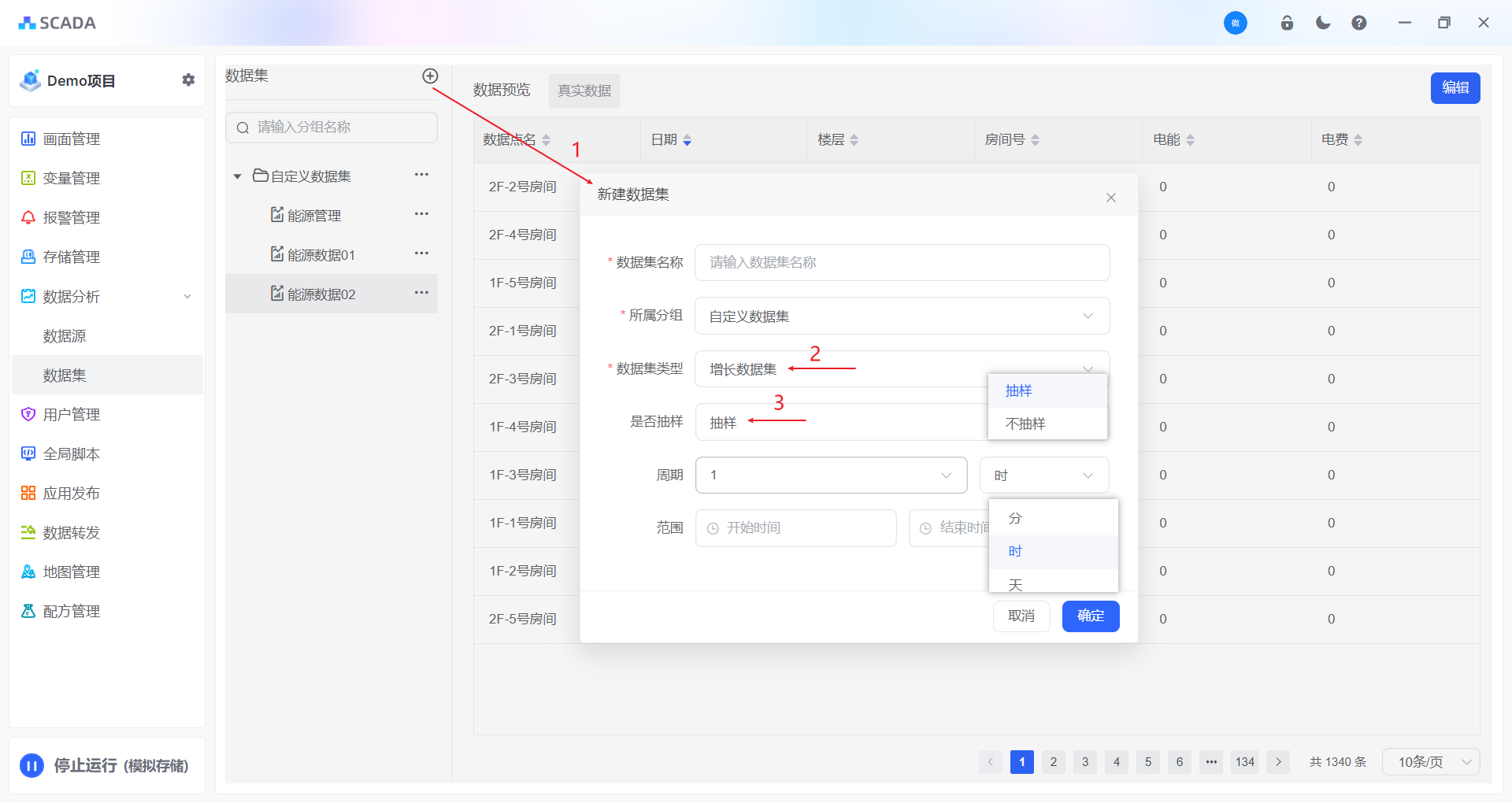
创建数据集
首先创建数据集,可以进行自定义分类 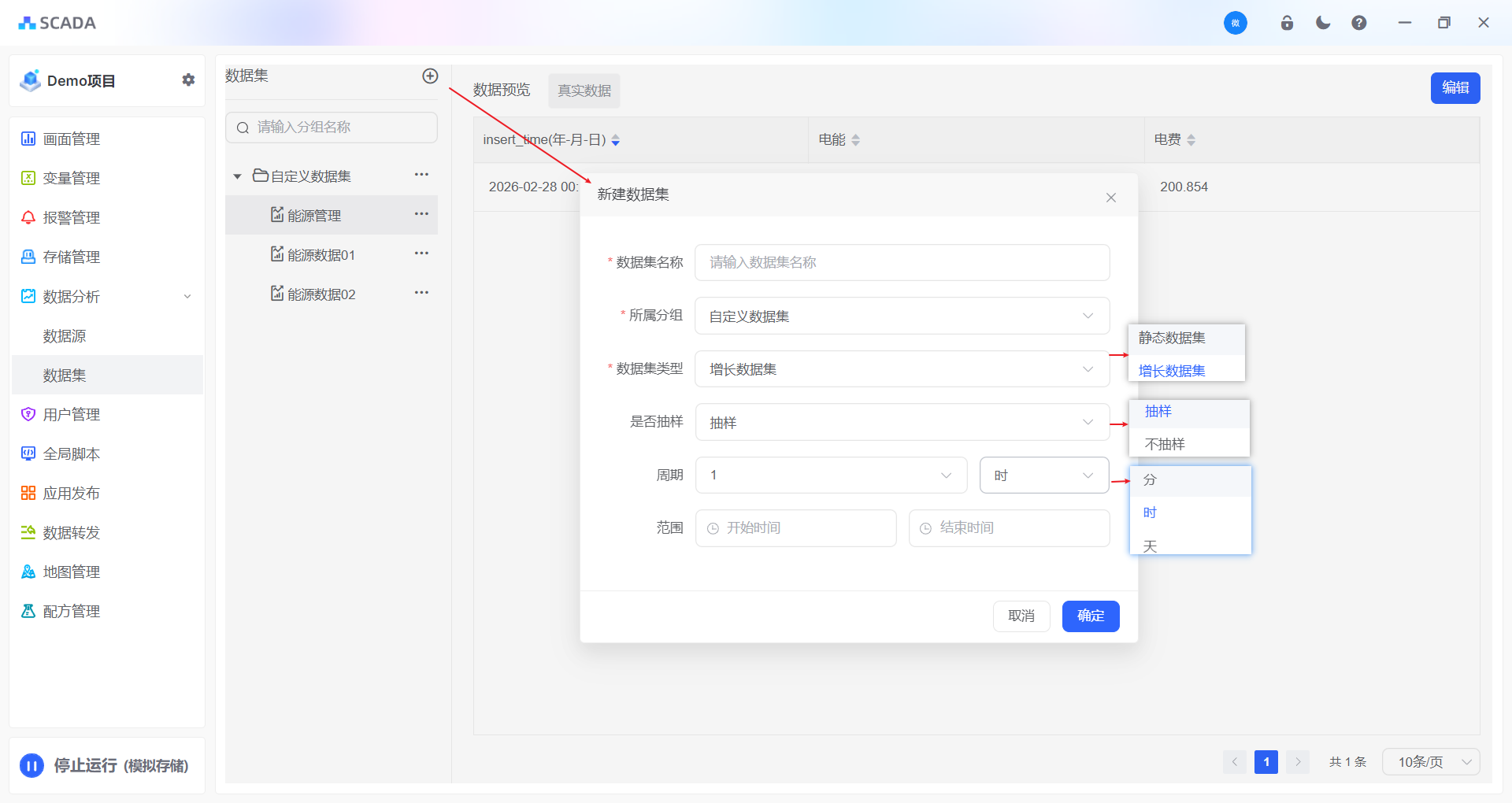
名词解释
静态数据集:数据不会随着时间的变化而增长,往往用于关系类数据
增长数据集:数据根据时间进行增长,往往用于变量类数据
周期:针对数据集数据,不支持太密集的秒级数据进入数据分析,故而需要对数据进行间隔取样。取样的周期:分钟、小时、天。
| 周期 | 时间段 |
|---|---|
| 分钟 | 1、5、10、30 |
| 小时 | 1、12 |
| 天 | 1 |
范围:默认全部时间段,如果只需要某个时间段的数据则进行设置即可。
编辑数据集
必要条件: 数据输入、数据输出、数据发布
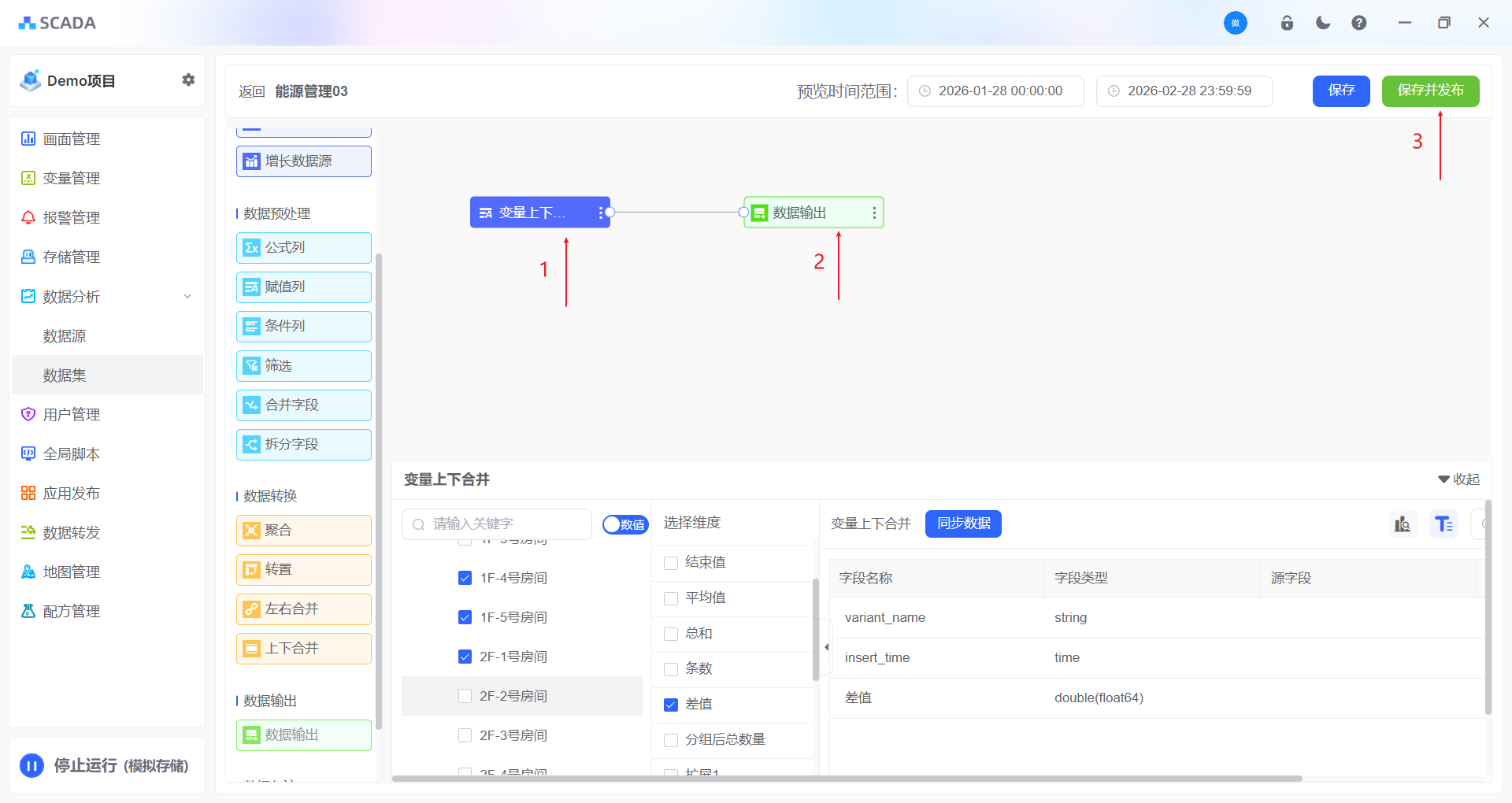
数据集功能分为4个节点、15项功能
| 数据输入 | 数据预处理 | 数据转换 | 数据输出 |
|---|---|---|---|
| 变量上下合并 | 公式列 | 聚合 | 数据输出 |
| 变量左右关联 | 赋值列 | 转置 | |
| 静态数据源 | 条件列 | 上下合并 | |
| 增长数据源 | 过滤 | 左右合并 | |
| 合并字段 | |||
| 拆分字段 |
数据输入
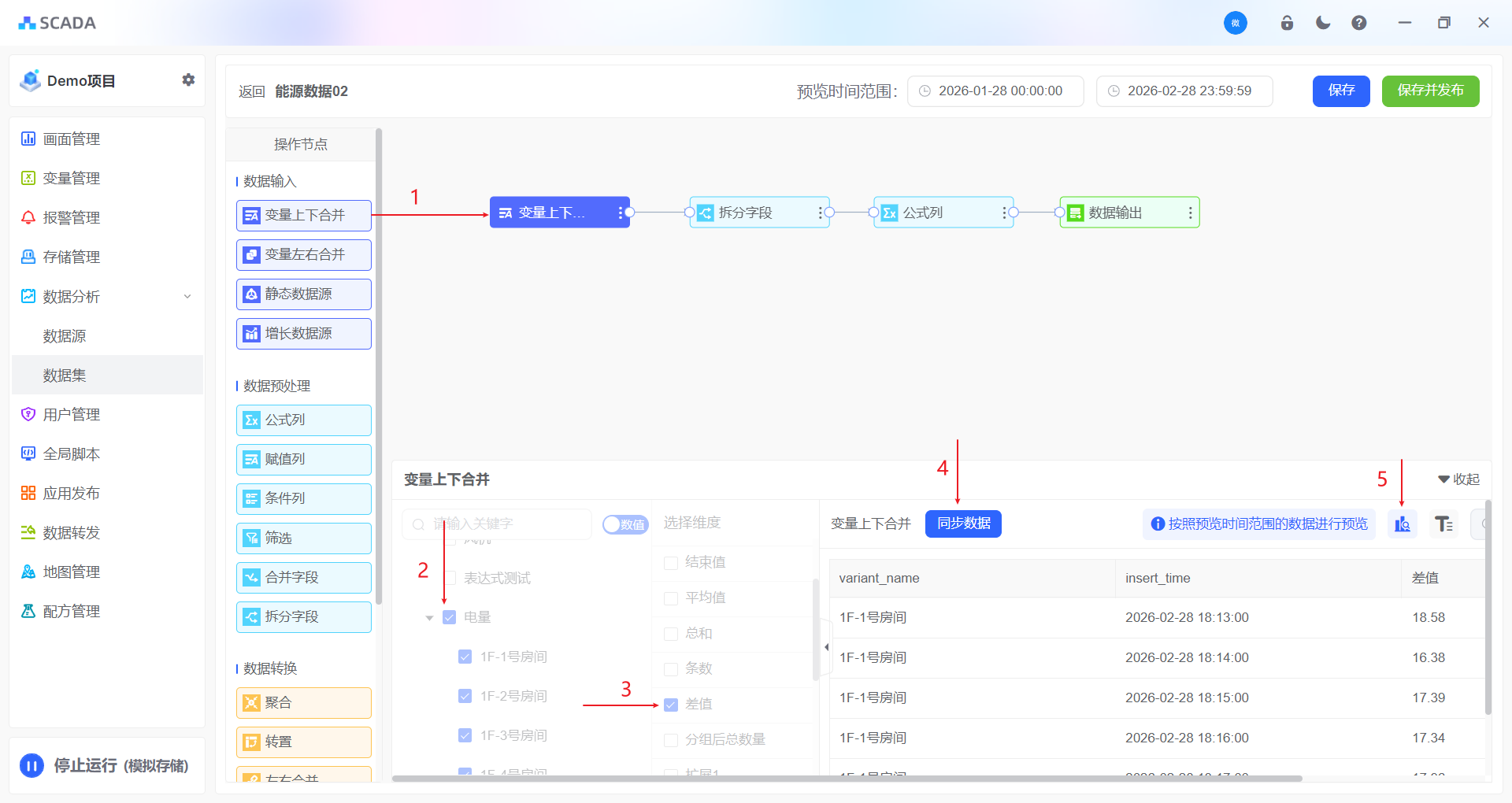
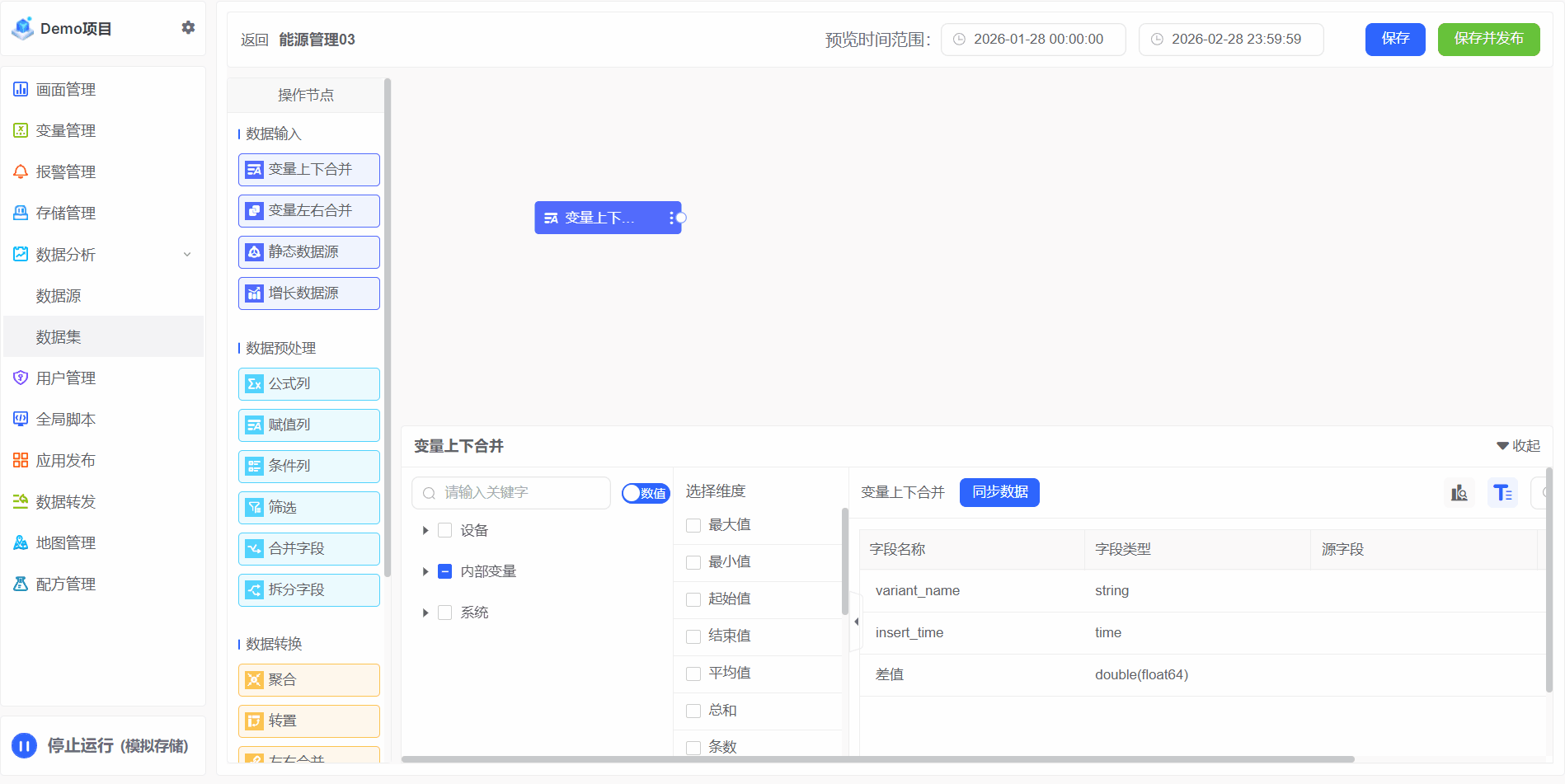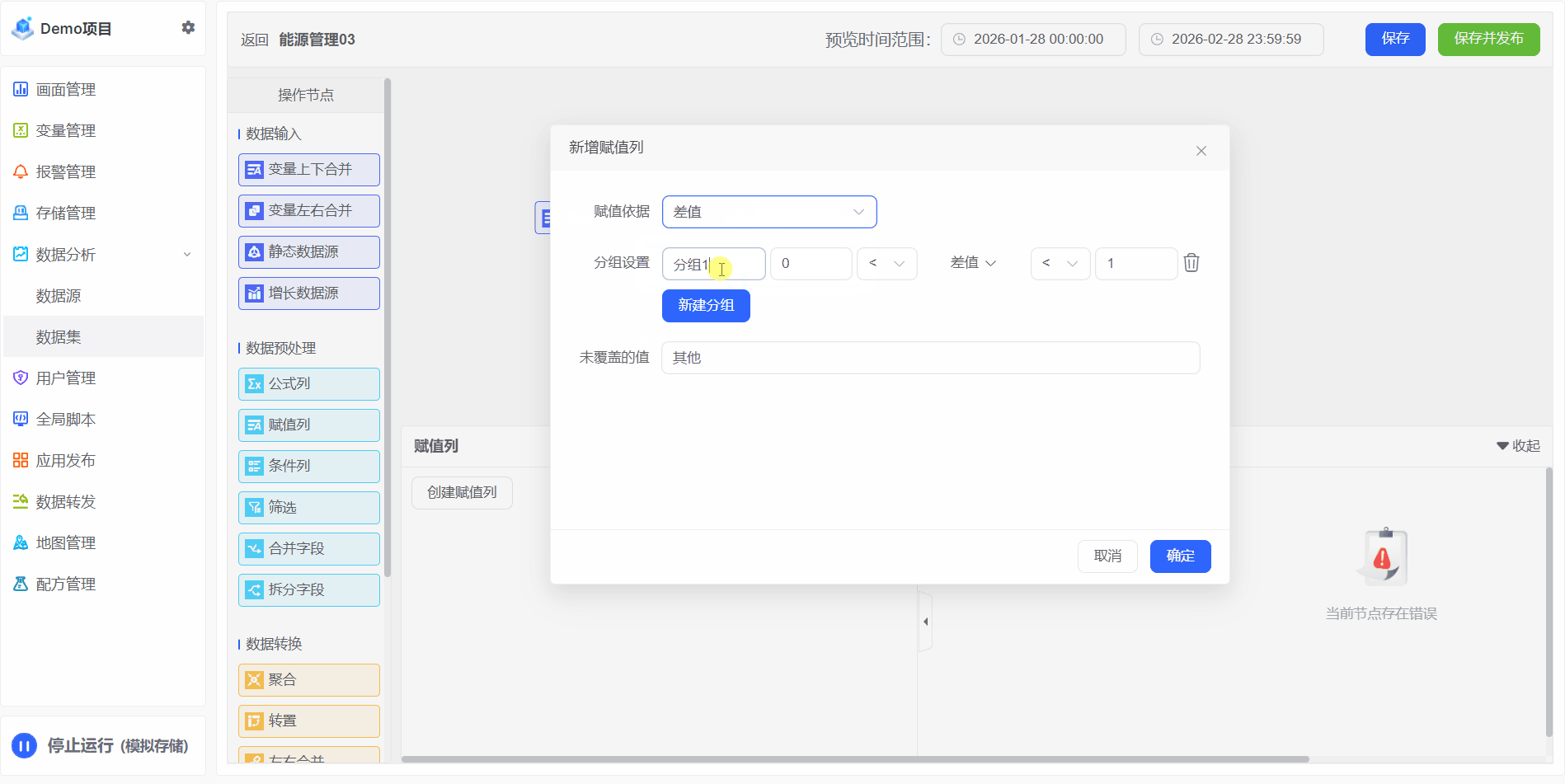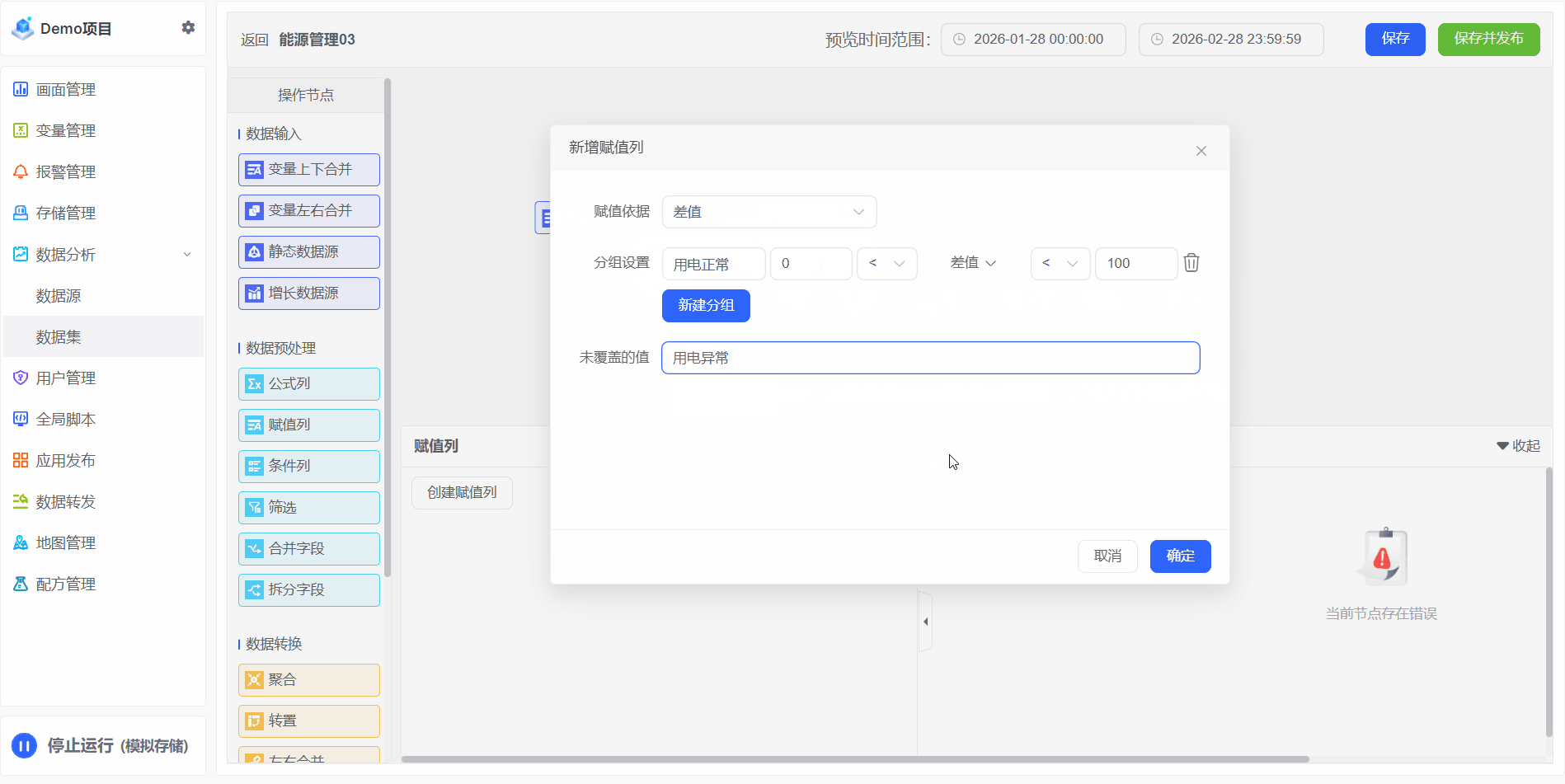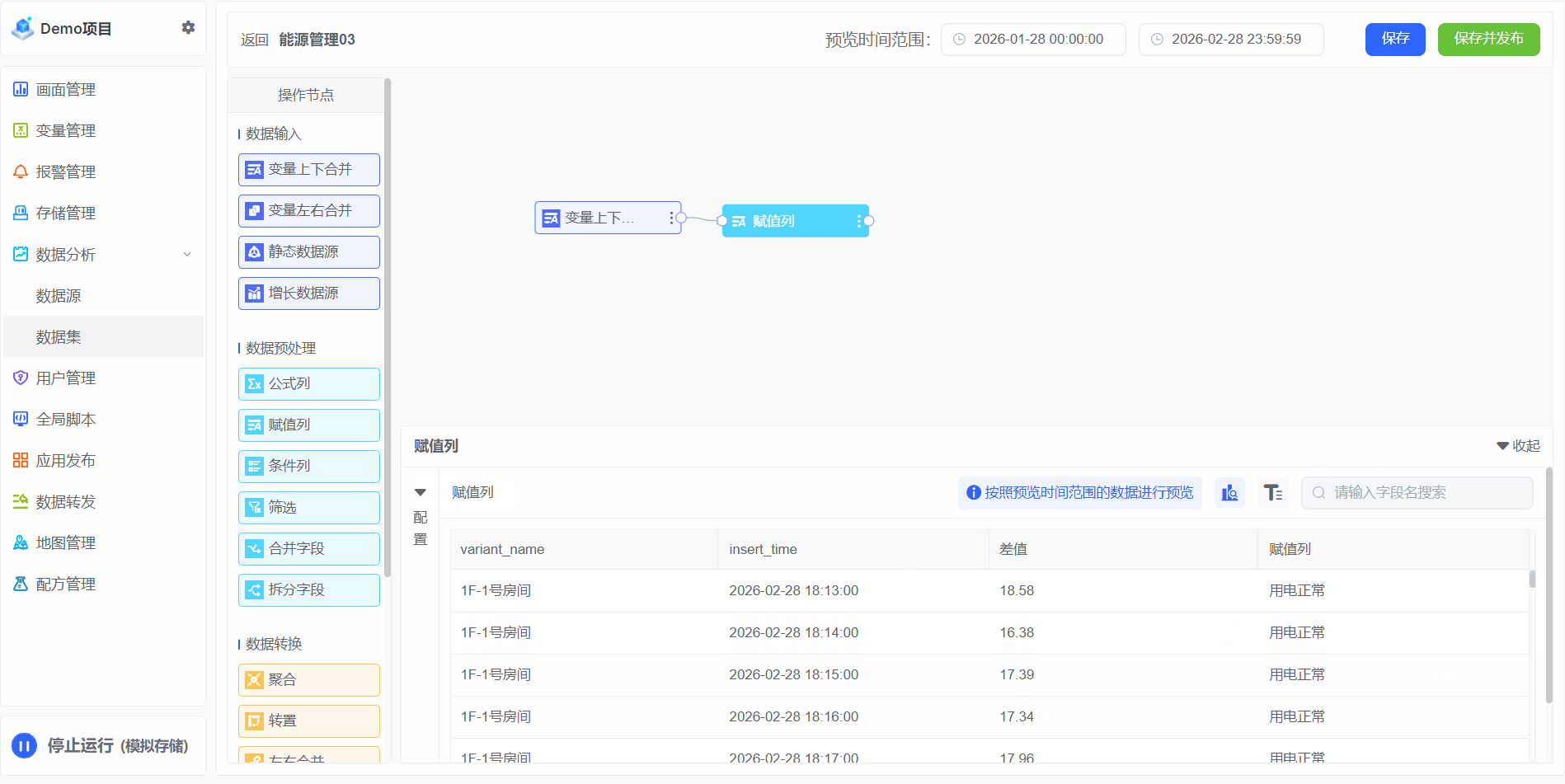
变量上下合并
针对的参与存储的变量,存储的方法参考存储管理,将两个及两个以上变量上下合并为同一张表,数据在列上扩展。遵循的规则:按照相同的字段合并
示例
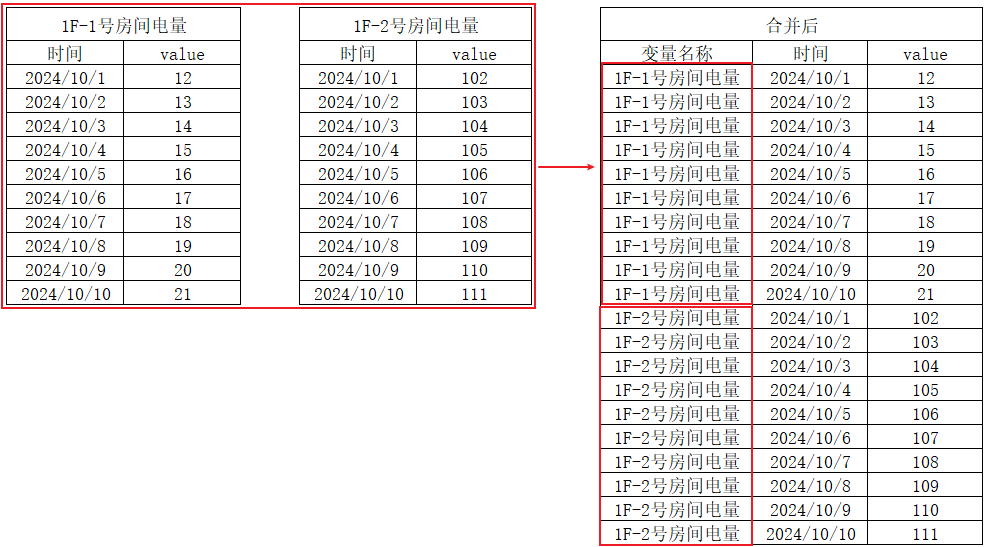
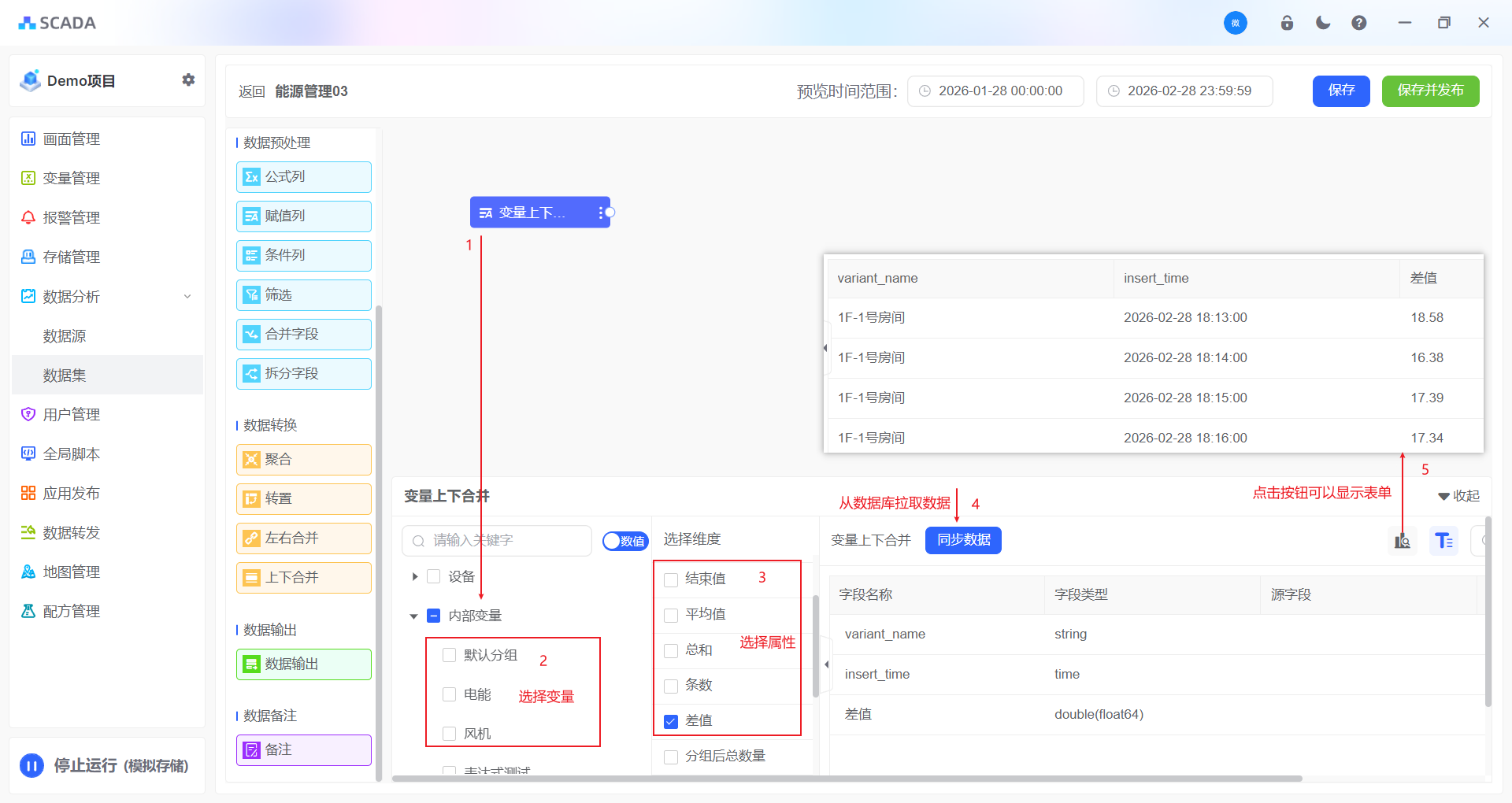 1、选择变量
1、选择变量
选择需要参与分析的变量,支持搜索和多选
2、选择维度
选择变量需要参与的属性
名词介绍
| 名词 | 说明 |
|---|---|
| 最大值 | 按照数据集的抽样周期为单位抽取最大值,示例:变量1秒/次,数据基抽样周期1分钟,那么从60条记录里面取1条最大值 |
| 最小值 | 按照数据集的抽样周期为单位抽取最小值,示例:变量1秒/次,数据基抽样周期1分钟,那么从60条记录里面取1条最小值 |
| 起始值 | 按照数据集的抽样周期为单位抽取起始值,示例:变量1秒/次,数据基抽样周期5分钟,起始值分别为:00:00、05:00、10:00 |
| 结束值 | 按照数据集的抽样周期为单位抽取起始值,示例:变量1秒/次,数据基抽样周期5分钟,起始值分别为:05:00、10:00、15:00 |
| 平均值 | 按照数据集的抽样周期为单位计算平均值,示例:变量1秒/次,数据基抽样周期1分钟,那么60条记录相加/60,计算出平均值 |
| 总和 | 按照数据集的抽样周期为单位计算求和值,示例:变量1秒/次,数据基抽样周期1分钟,那么60条记录相加,计算出总和 |
| 条数 | 按照数据集的抽样周期为单位计数,示例:变量1秒/次,数据基抽样周期1分钟,那计数为60 |
| 差值 | 按照数据集的抽样周期为单位,用最小值-最大值,示例:变量1秒/次,数据基抽样周期1分钟,差值为:01:00-00:00 |
| 分组后总数量 | |
| 扩展 | 变量的扩展字段,相当于对变量的一种标记或者分组 |
示例
波峰电压/波峰电流:最大值
波谷电压/波谷电流:最小值
抄表数据:结束值
开机数据:起始值
分钟温度趋势:平均值
每天的用电量:每小时电量的差值总和
同一个状态发生的次数:条数
使用电量/使用水量:差值
3、同步数据
同步数据操作会从数据库随机拉取部分的数据,形成临时表、用于展示当前合并的结果样式
4、保存
保存当前的操作步骤,不会生成最终的数据集
变量左右合并
针对的参与存储的变量,存储的方法参考存储管理,将两个及两个以上变量左右合并为同一张表,数据在行上扩展。遵循的规则:按照相同的字段关联
示例
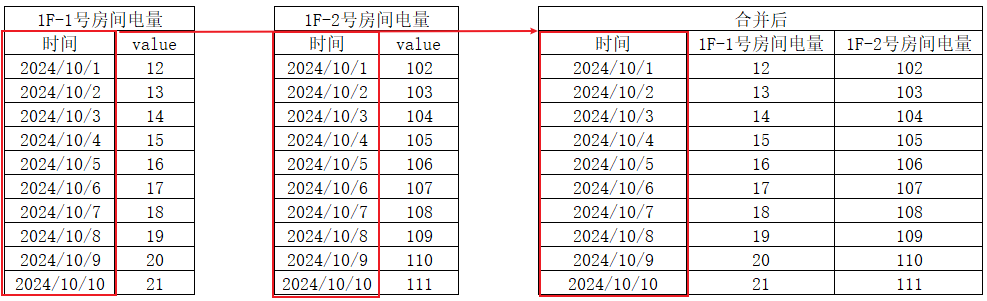
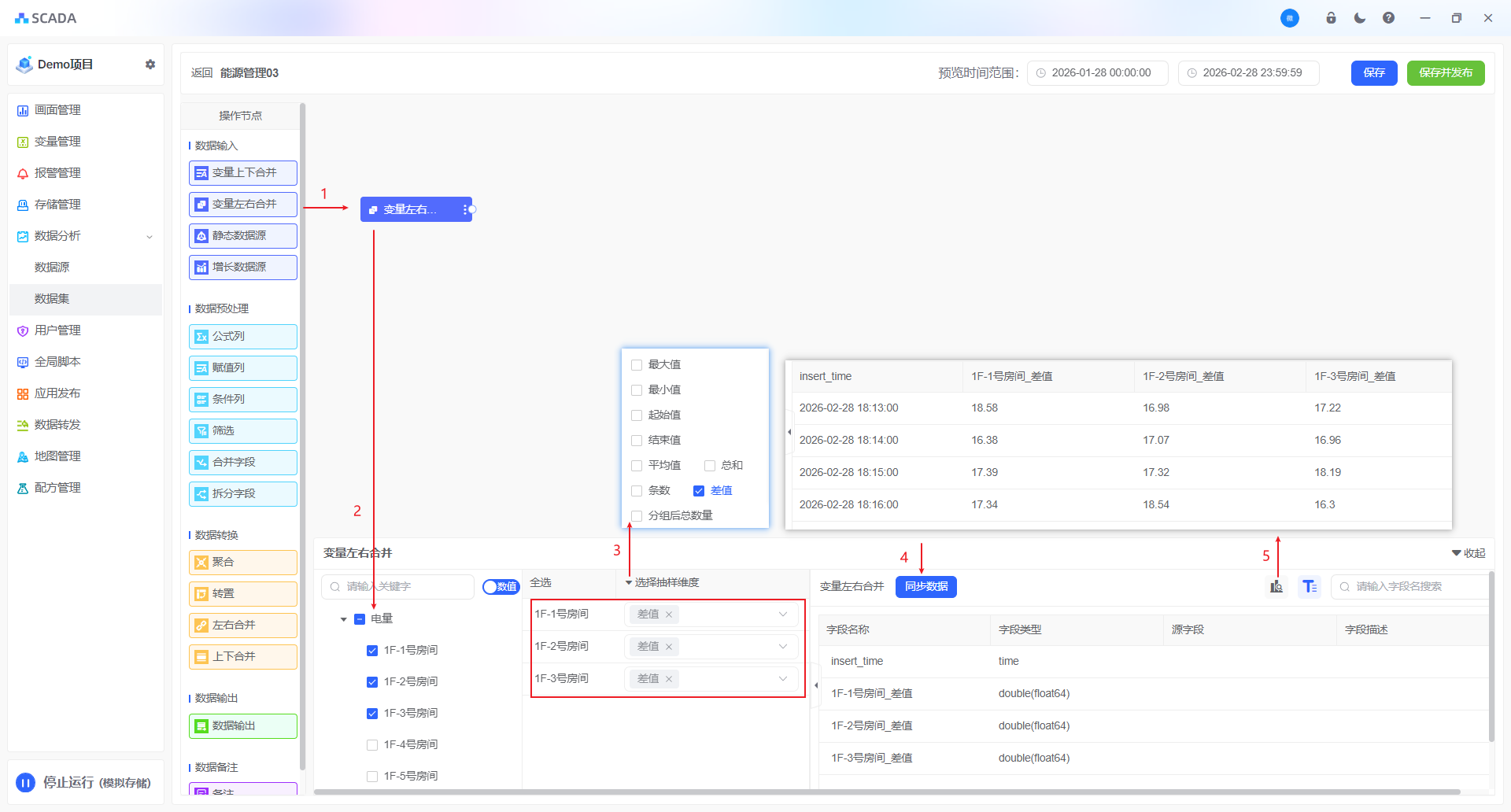
操作步骤以及名称解释参考变量上下合并
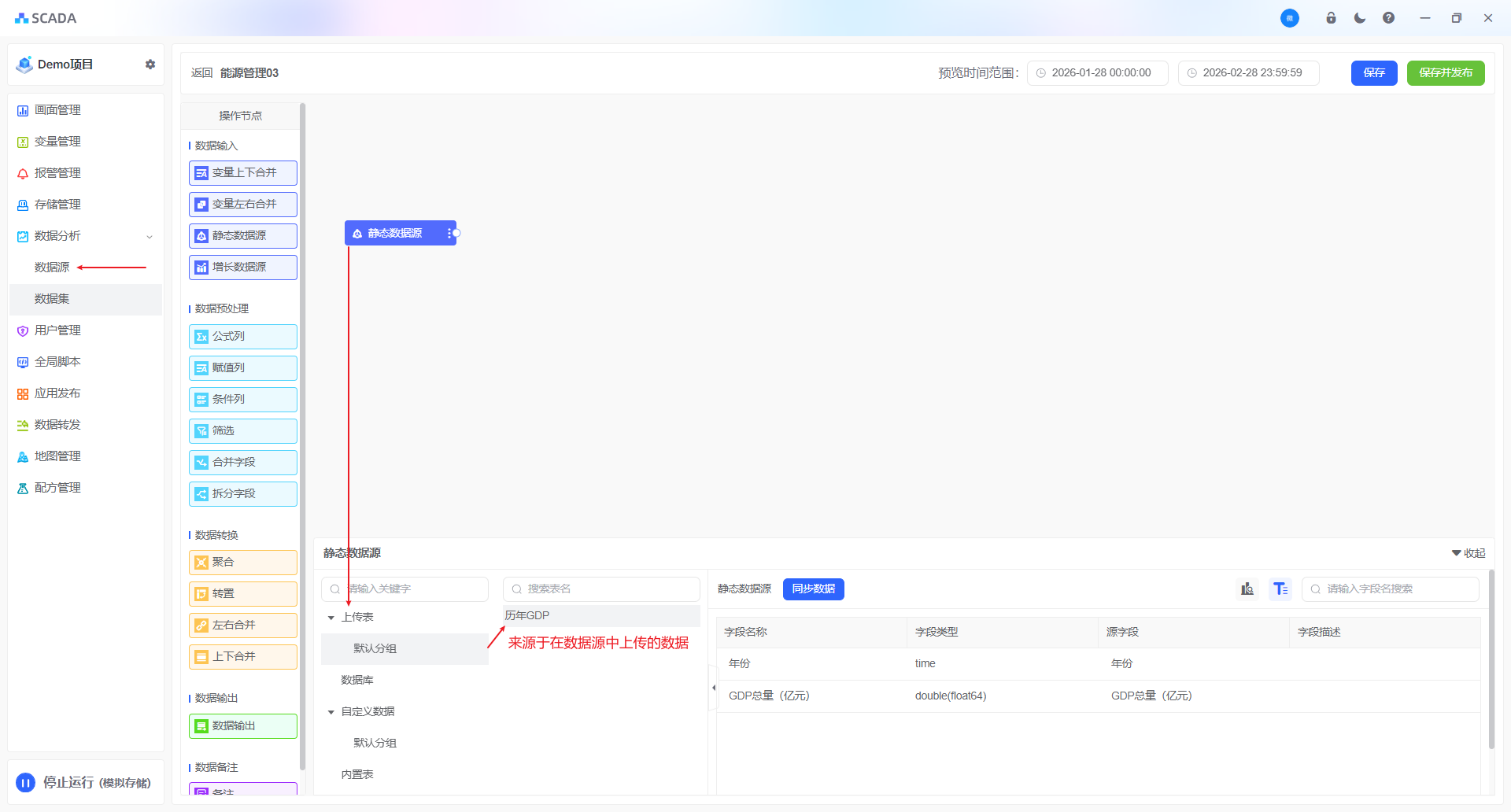
静态数据源
数据不随时间的增长而增长的数据源,也称之为静态数据。常用于Excel表格,或者第三方静态数据库。
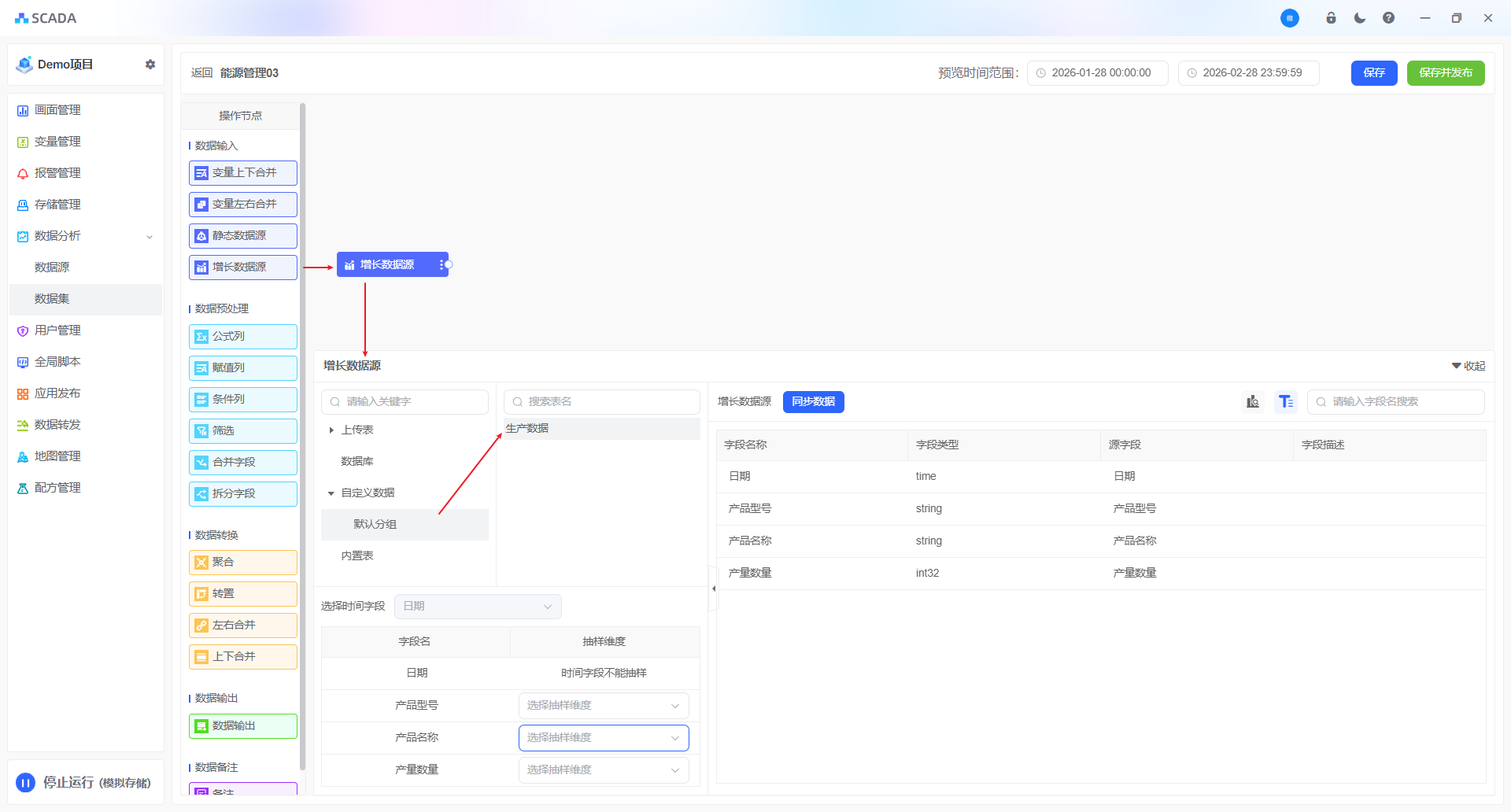
增长数据源
数据会随时间的增长而增长的数据源,也称之为动态数据。常用于变量存储,或者第三方动态数据库。
数据预处理
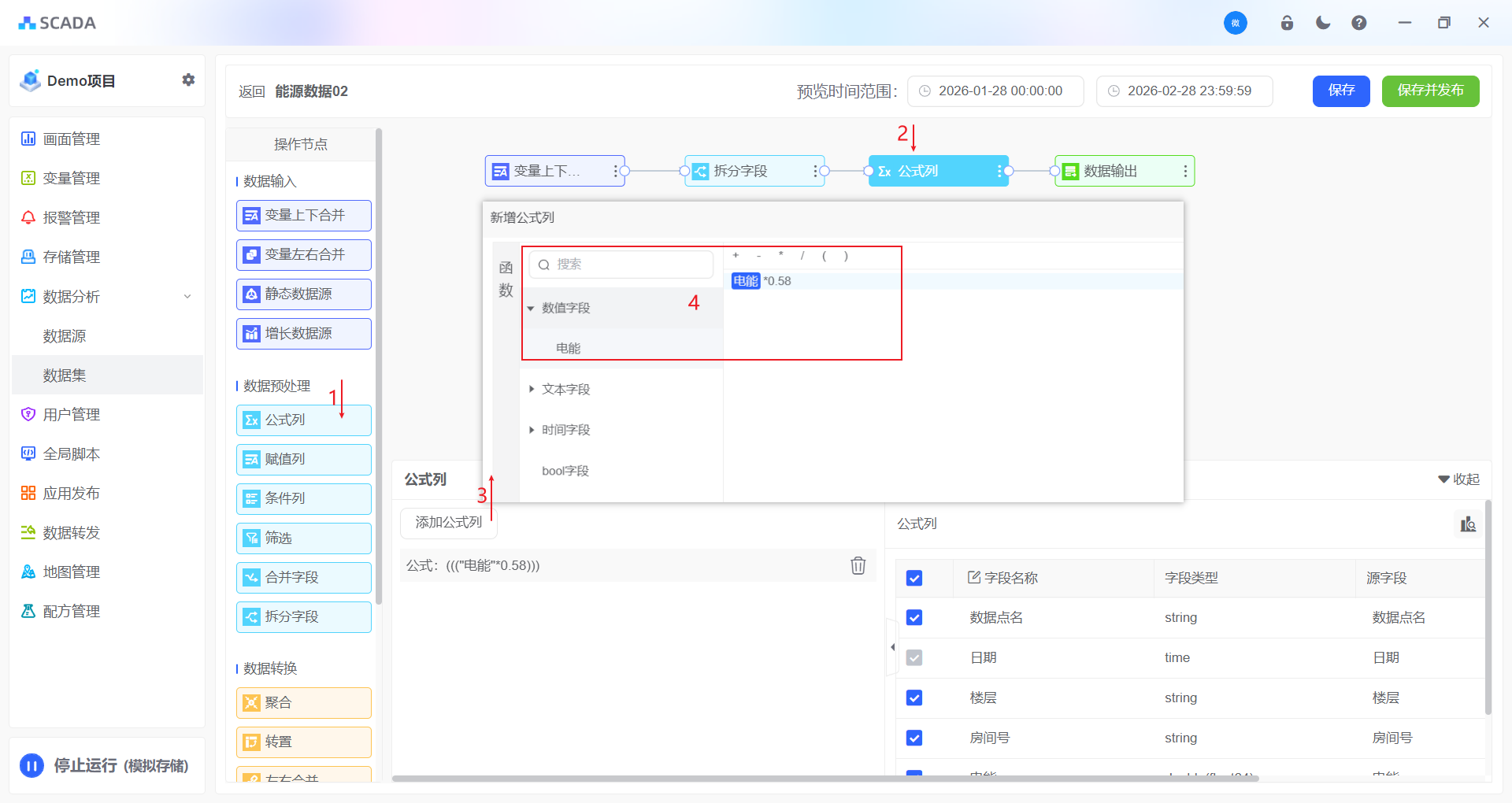
公式列
如果您需要对某一列的数据进行计算,那么就需要用到公式列,输入对应的计算规则,然后会在原来的表在新增一列出来。
支持的计算公式:
示例
根据电量计算电费 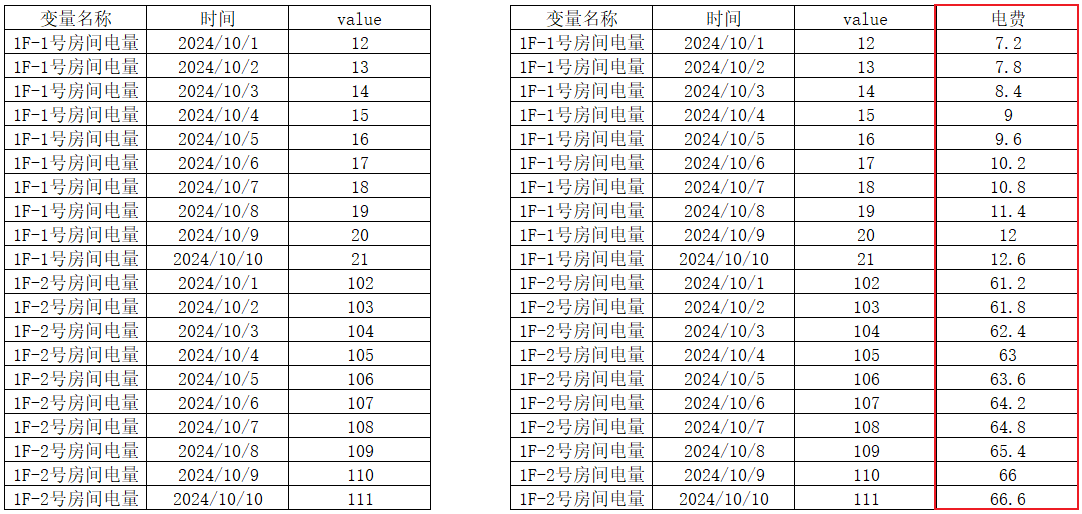
根据电量乘以系数0.58计算电费,操作步骤如下: 
支持新增列的重命名
赋值列
根据用户定义的映射规则,将源字段的值转换为新的分类/标签/区间,并输出为一个独立的新列,将原始数据转化为具有业务意义的分类标签,为后续的汇总、钻取、可视化提供结构化支持。无论是地理区域划分、客户分层,还是绩效评级,赋值列都提供了高效、灵活且易维护的手段
如果您需要根据某一列的内容进行静态分类,那么就需要用赋值列实现此功能。
1、例如:5台电表中的4台属于办公区域、其他属于生产区域。
2、例如:实际电量超过0~100之间,则标记用电正常,范围之外标记为用电异常
条件列
根据预设条件,对每一行数据进行判断,并返回对应的结果,从而创建一个新列,对将始数据进行智能分类、打标和增强,为后续的可视化分析、切片、聚合提供更丰富的维度支持。
如果您需要根据某一列的内容进行动态分类,那么就需要用条件列实现此功能。
1、例如:1F属于工业用电,用电量超过4000标记为正常生产、低于4000标记为异常生产
2~4F属于生活用电,用电量0~3000标记为正常用电、超过3000标记为异常用电
2、例如:用电量低于3000部分0.56元计费,3000~4500部分0.63计费,超过4500以上部分,电费按照0.87元计费,
筛选
过滤功能用于根据指定条件筛选数据,仅保留满足条件的记录,从而减少数据复杂性,聚焦与分析目标最相关的信息。通过过滤,可排除不相关或次要数据,更清晰地识别模式、趋势和异常。需注意,该功能本身不支持日期过滤;如需按日期筛选,应在画面编辑器中通过其他方式实现。
1、例如:月用电低于10,属于电损,不参与统计 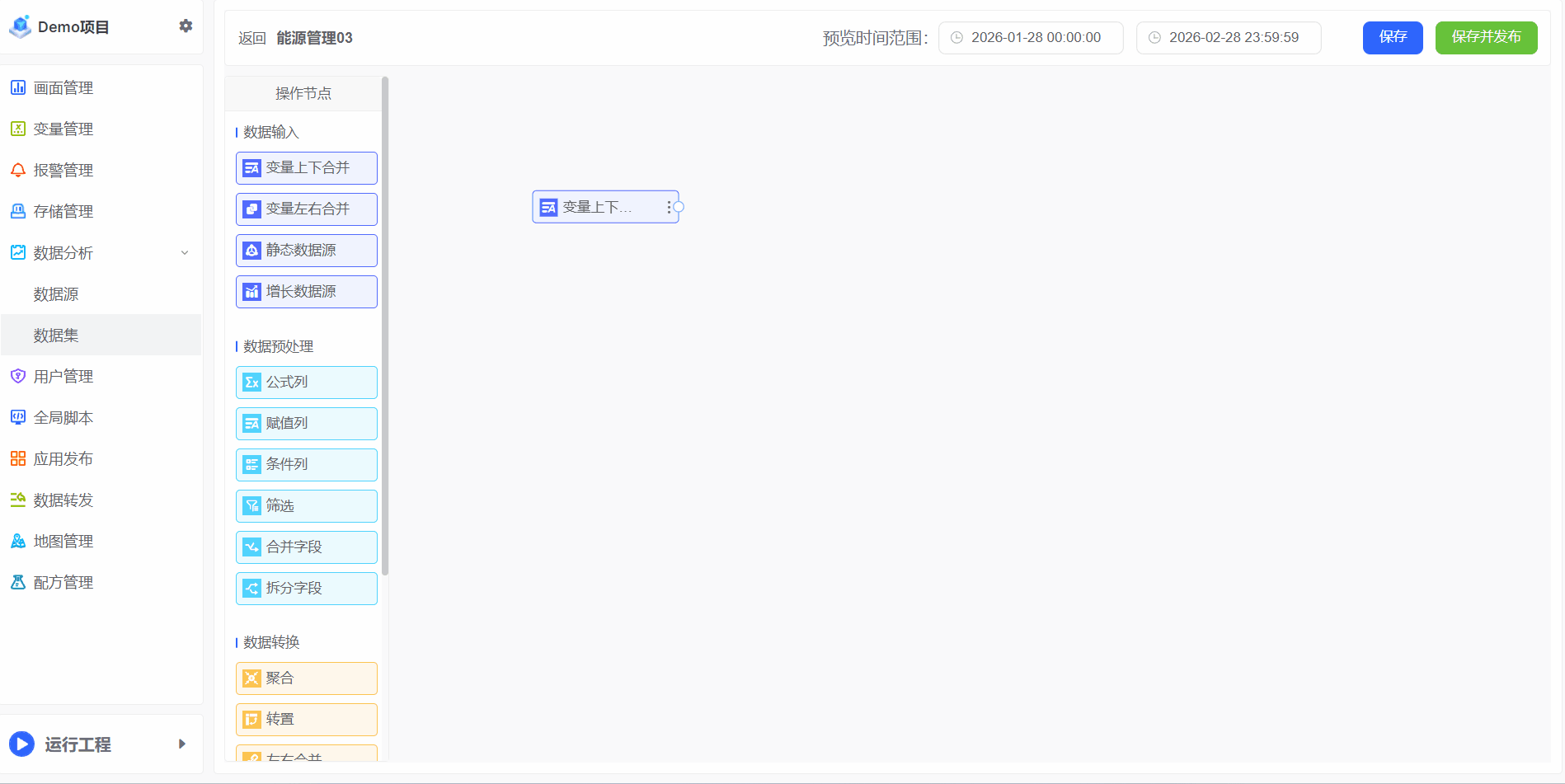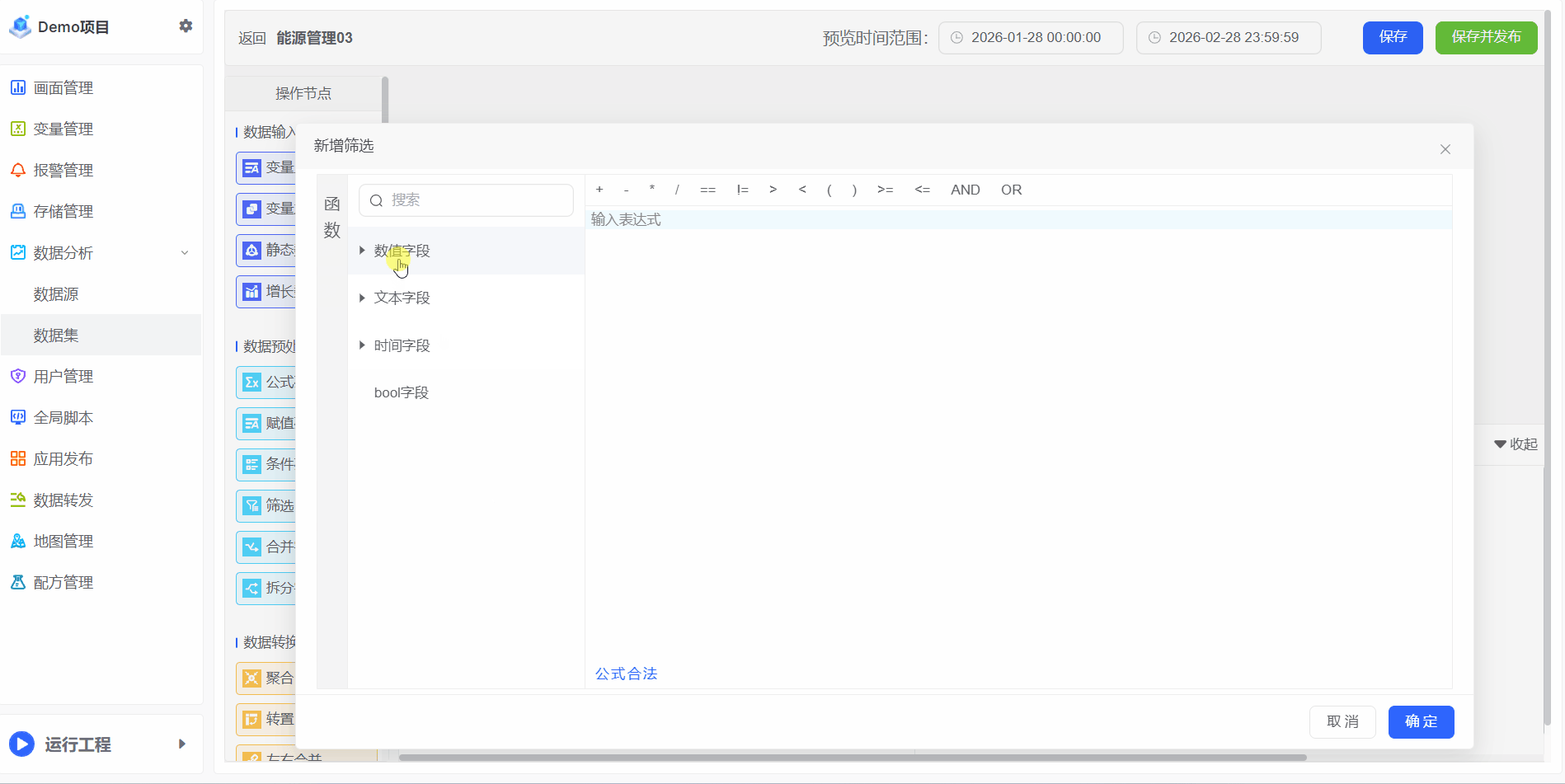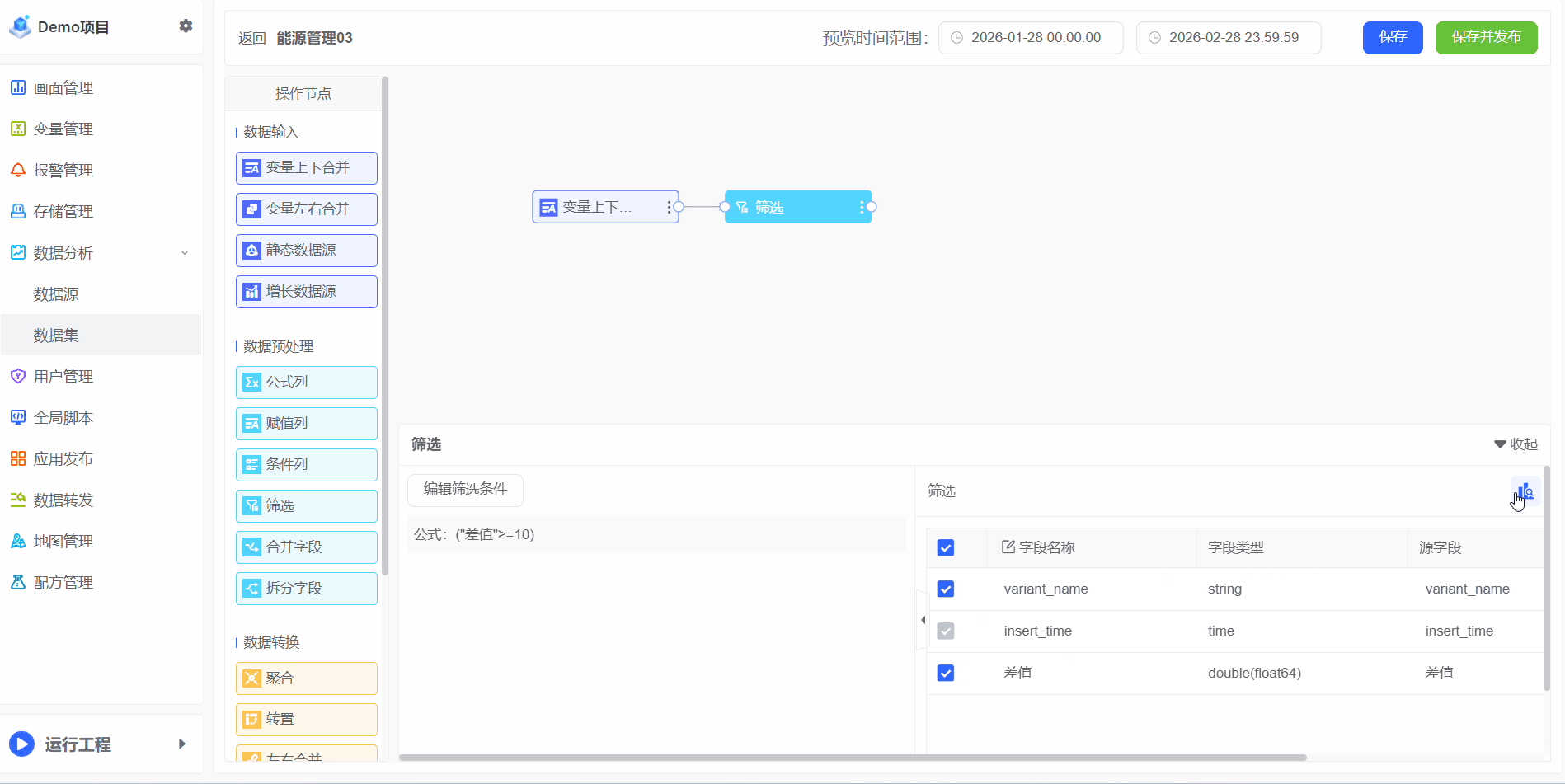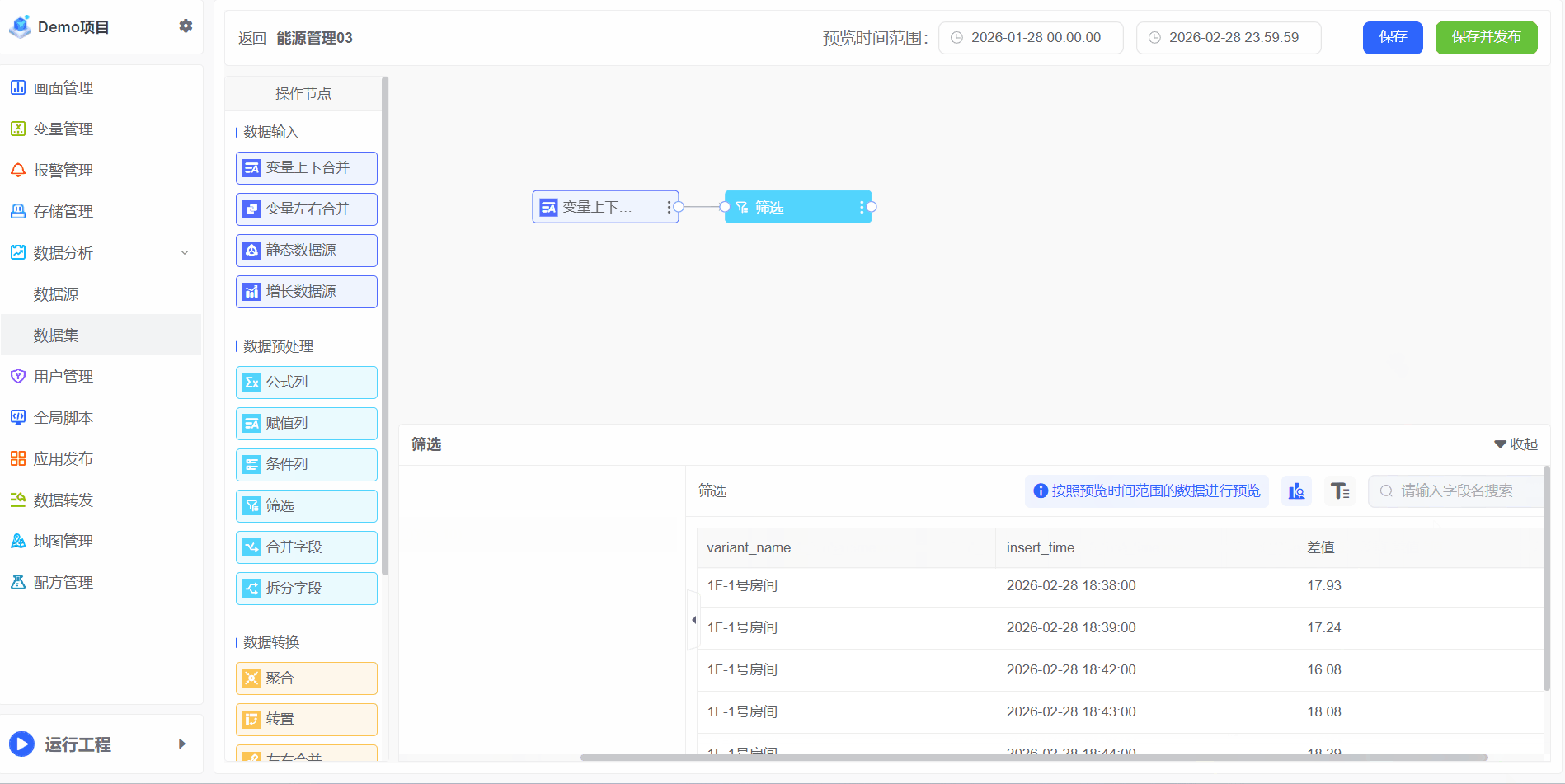
2、例如:计算3楼电表的时候,其他楼层电表不参与统计 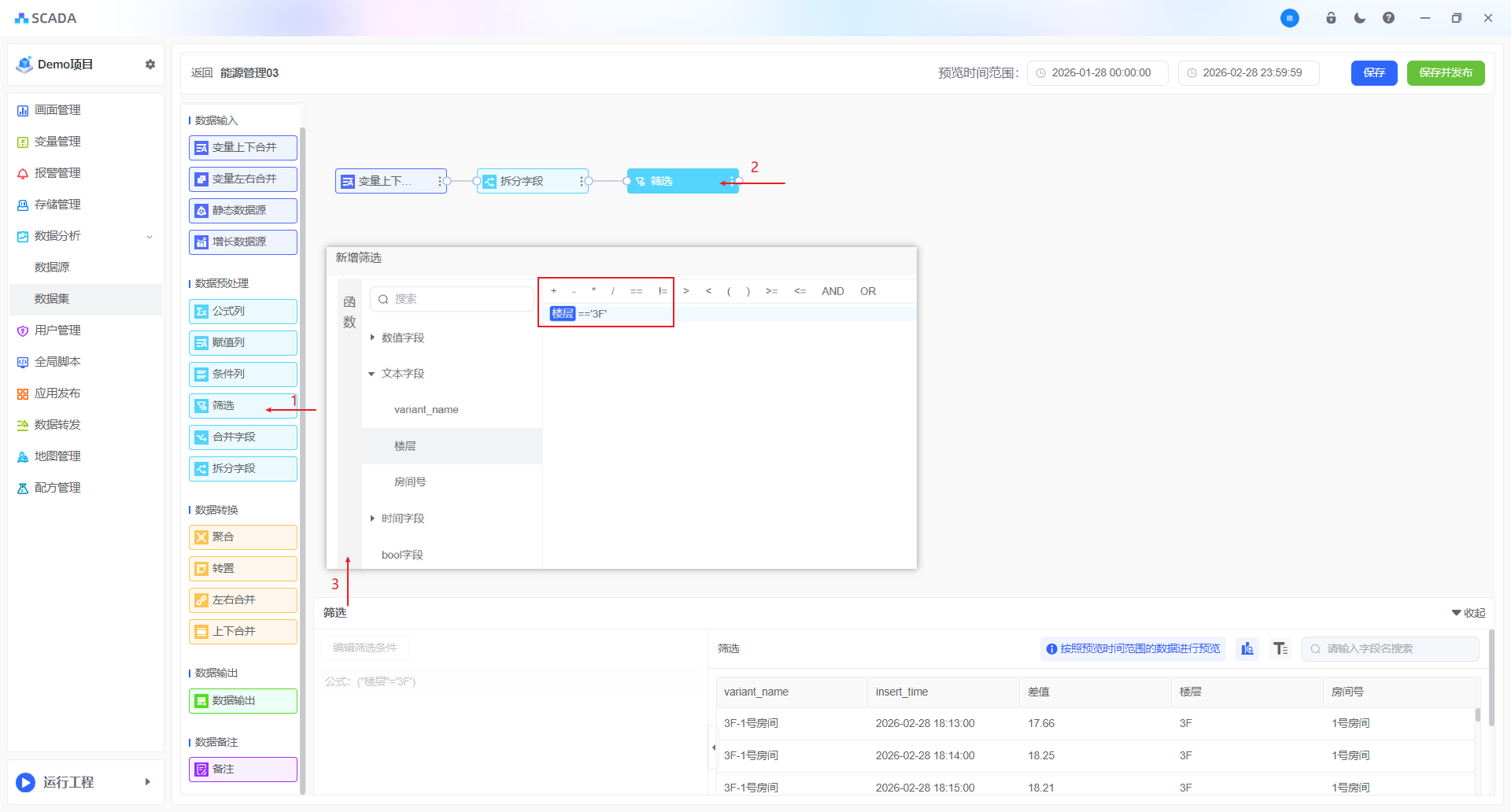
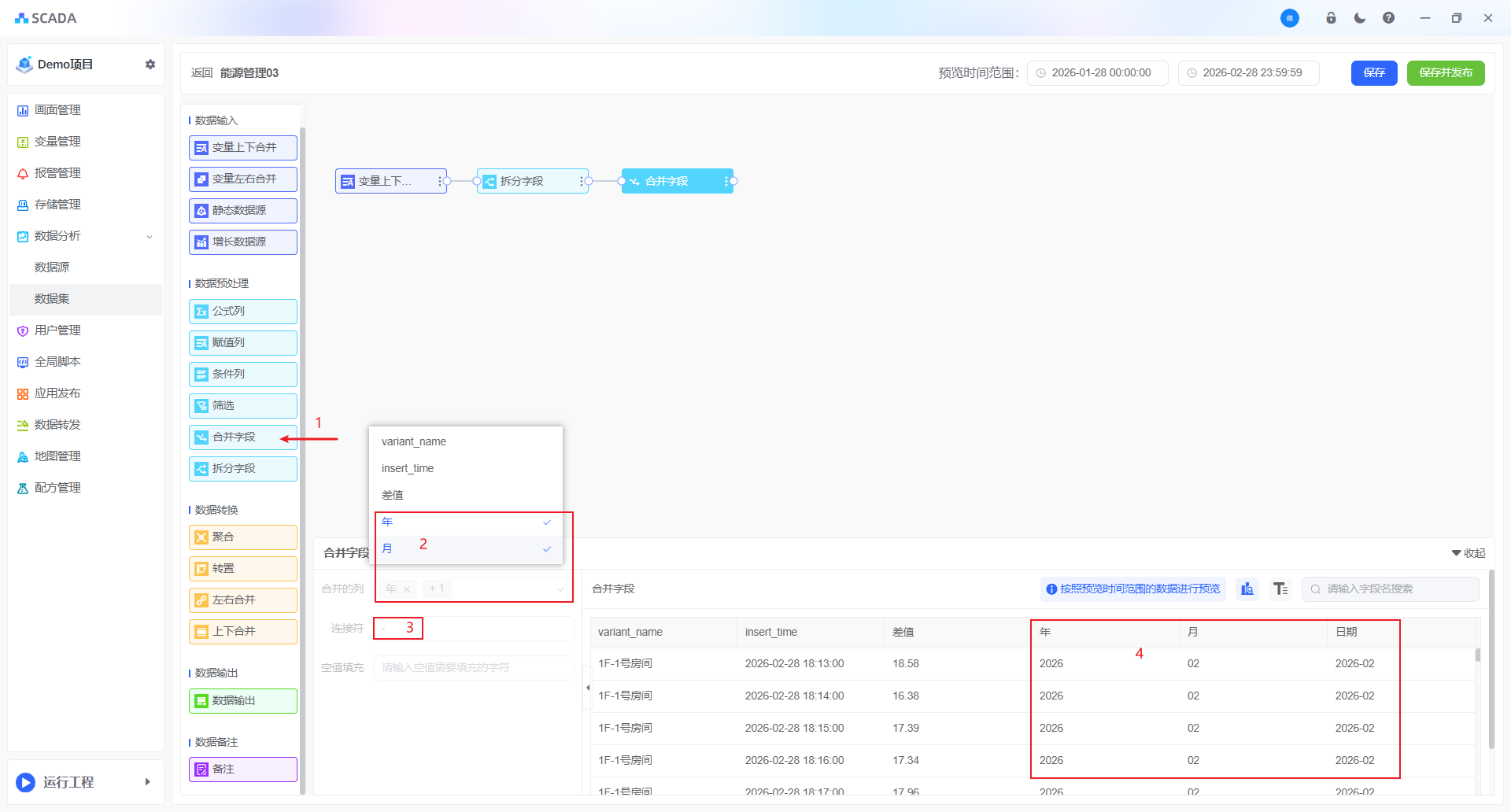
合并字段
当需要将两个或多个字段的内容整合为一个新字段时,可使用字段合并功能。该功能支持多种数据类型,包括:数值型、字符串型和日期型字段
合并的列: 选择需参与合并的一个或多个字段(列),系统将按所选顺序依次拼接其内容
连接符: 可自定义各字段之间的分隔字符(如空格、逗号、短横线等),用于提升合并后内容的可读性
空值填充: 当某字段值为空(NULL 或空白)时,可指定替代内容(如“—”、“无”或自定义文本),避免合并结果中出现缺失或格式错乱。若不设置,默认将忽略空值或以空字符串处理。
例如:日期的年月日和时间是分成多列的,通过合并字段添加分隔符“-”将时间合并为一列
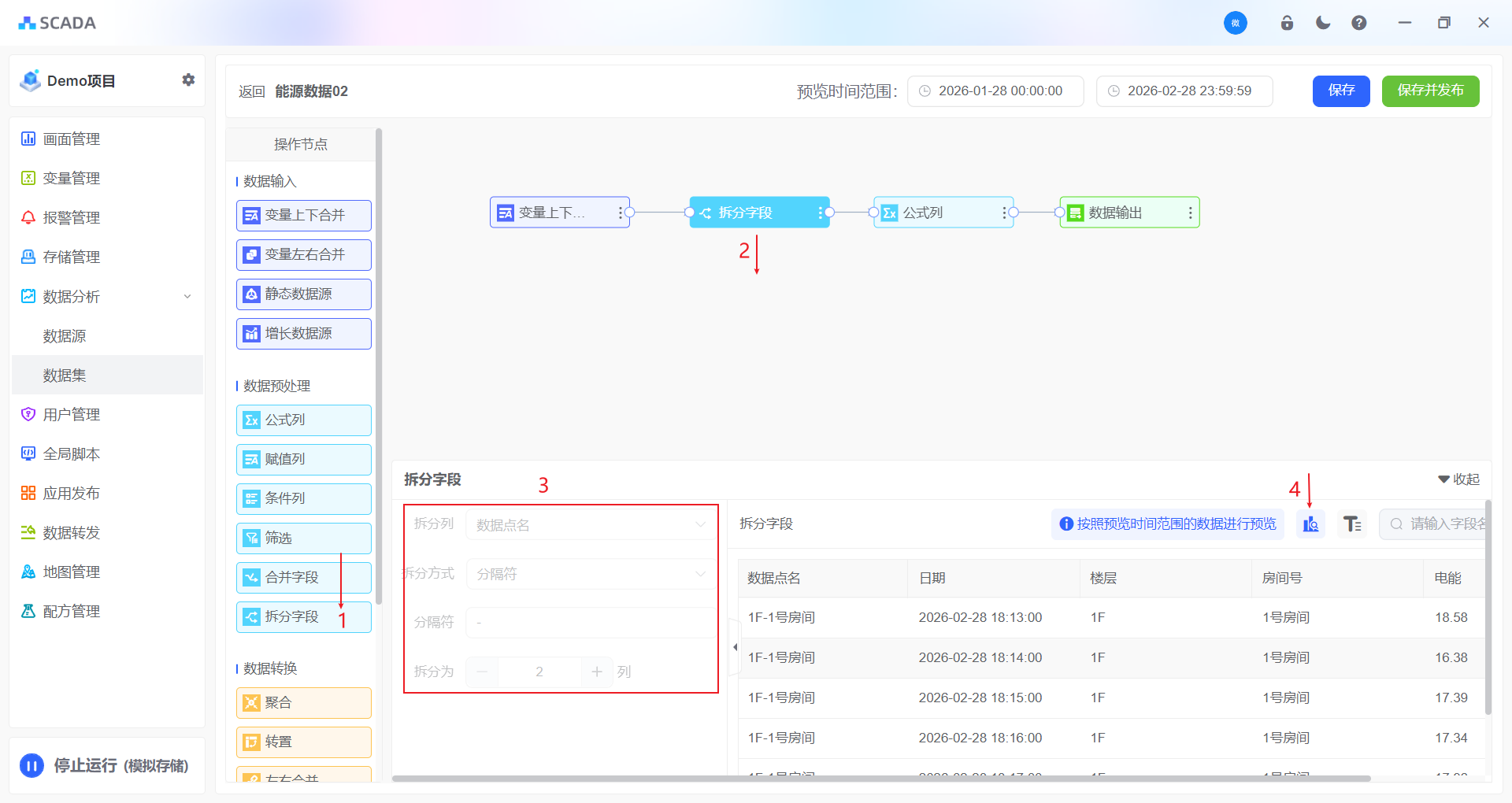
拆分字段
当需要将一个字段的内容拆分为多个独立字段时,请使用字段拆分功能。该功能支持对字符串、数值和日期类型的字段进行拆分
拆分列:选择需要拆分的源字段。
拆分方式:依据指定字符(如逗号、空格、短横线等)将字段内容切分为多段/根据固定字符位置或长度进行分割(适用于编码、ID 等结构化文本)
分隔符:源字段中-空格、逗号、短横线等
索引:源字段中第n个字符
例如:将变量的名称按照楼层进行拆分,便于分区统计 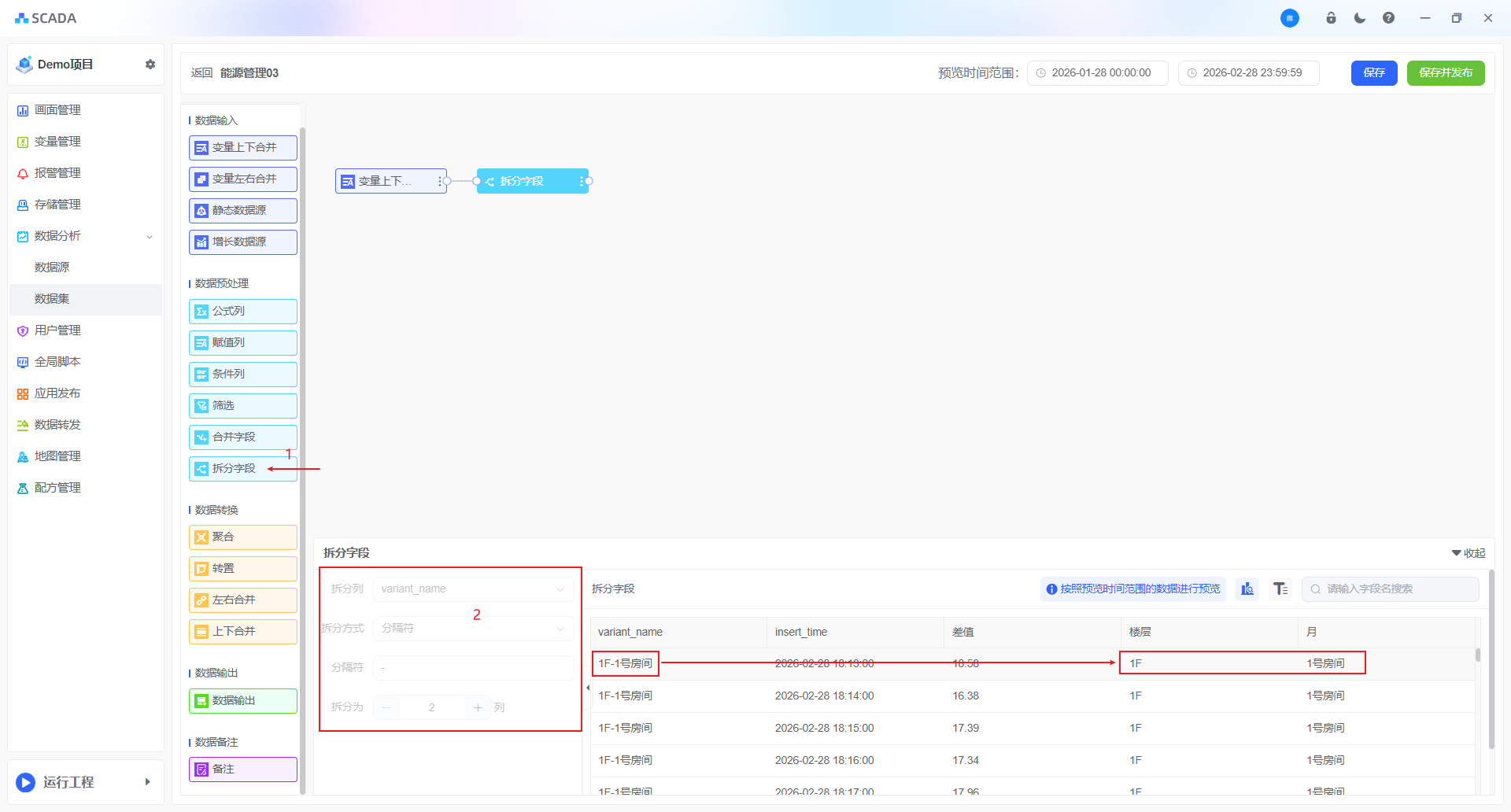
数据转换
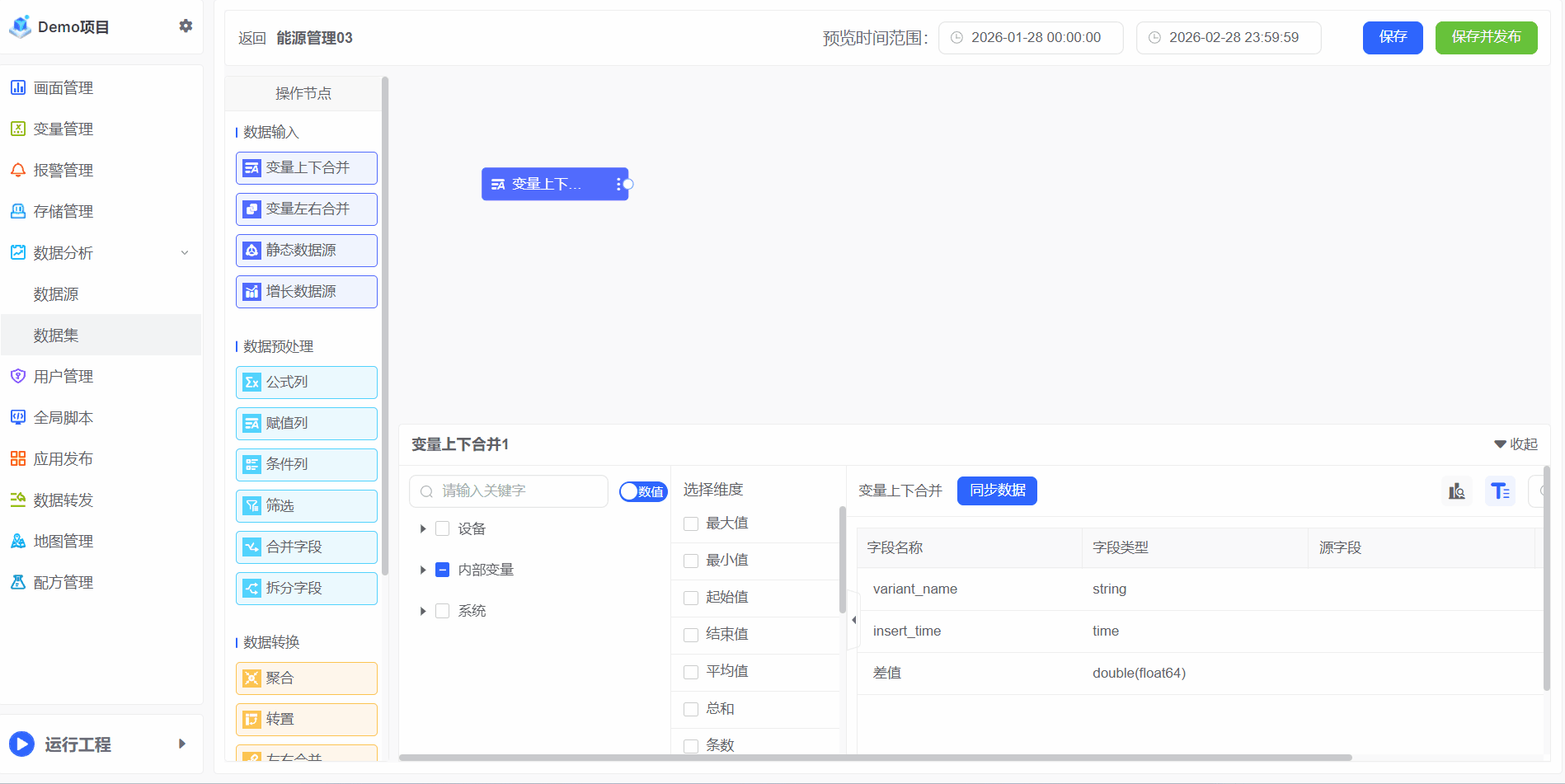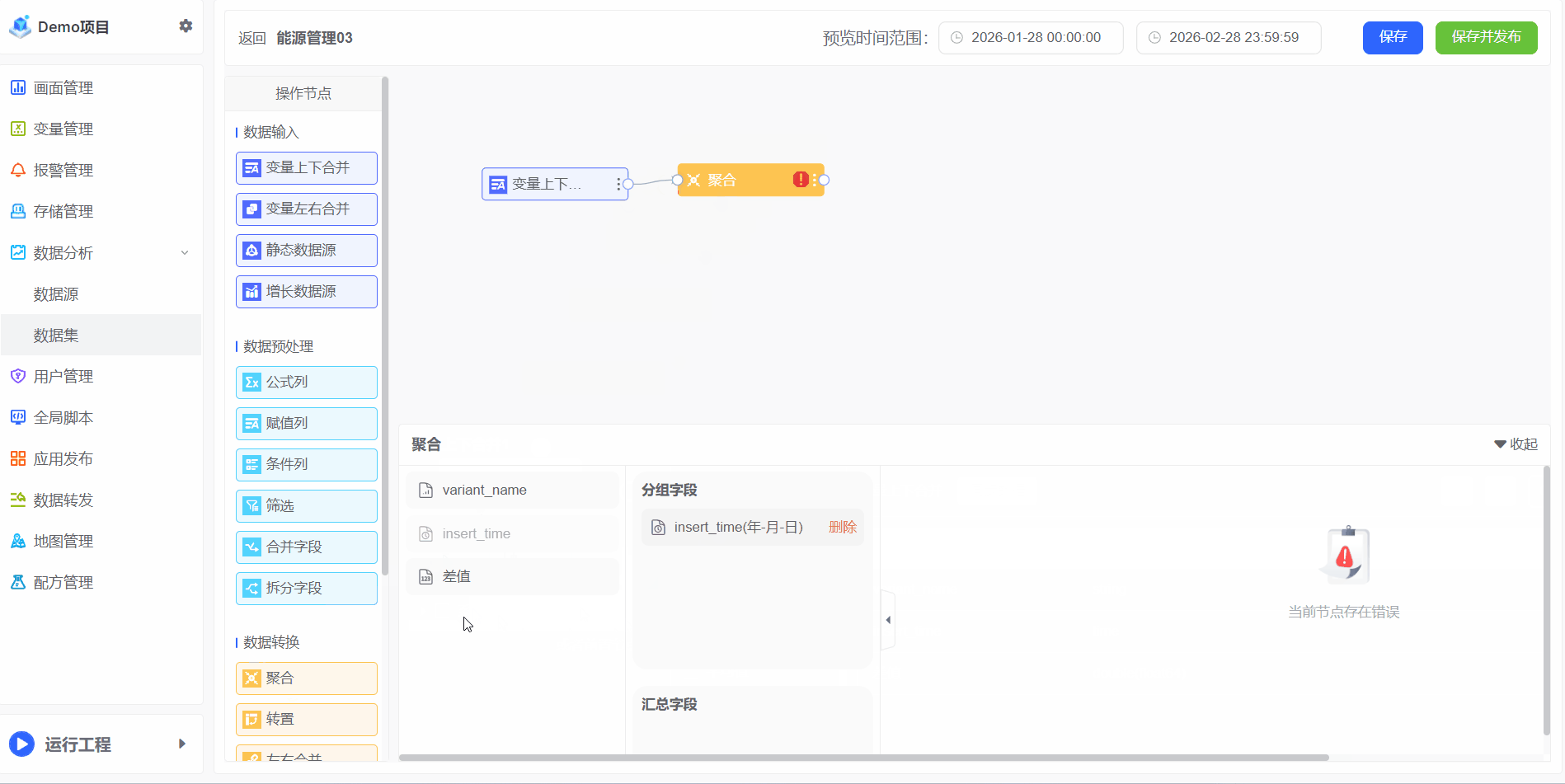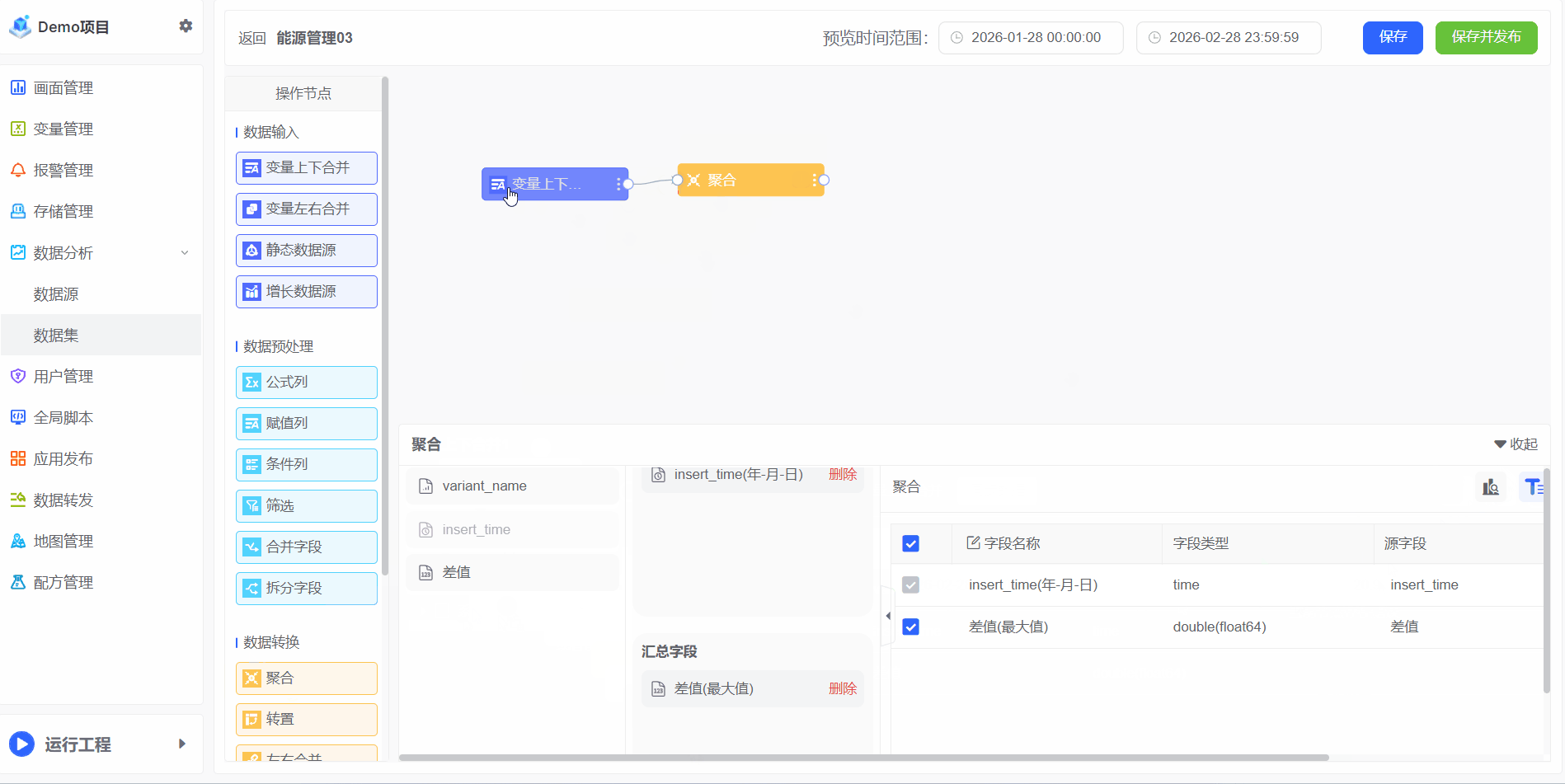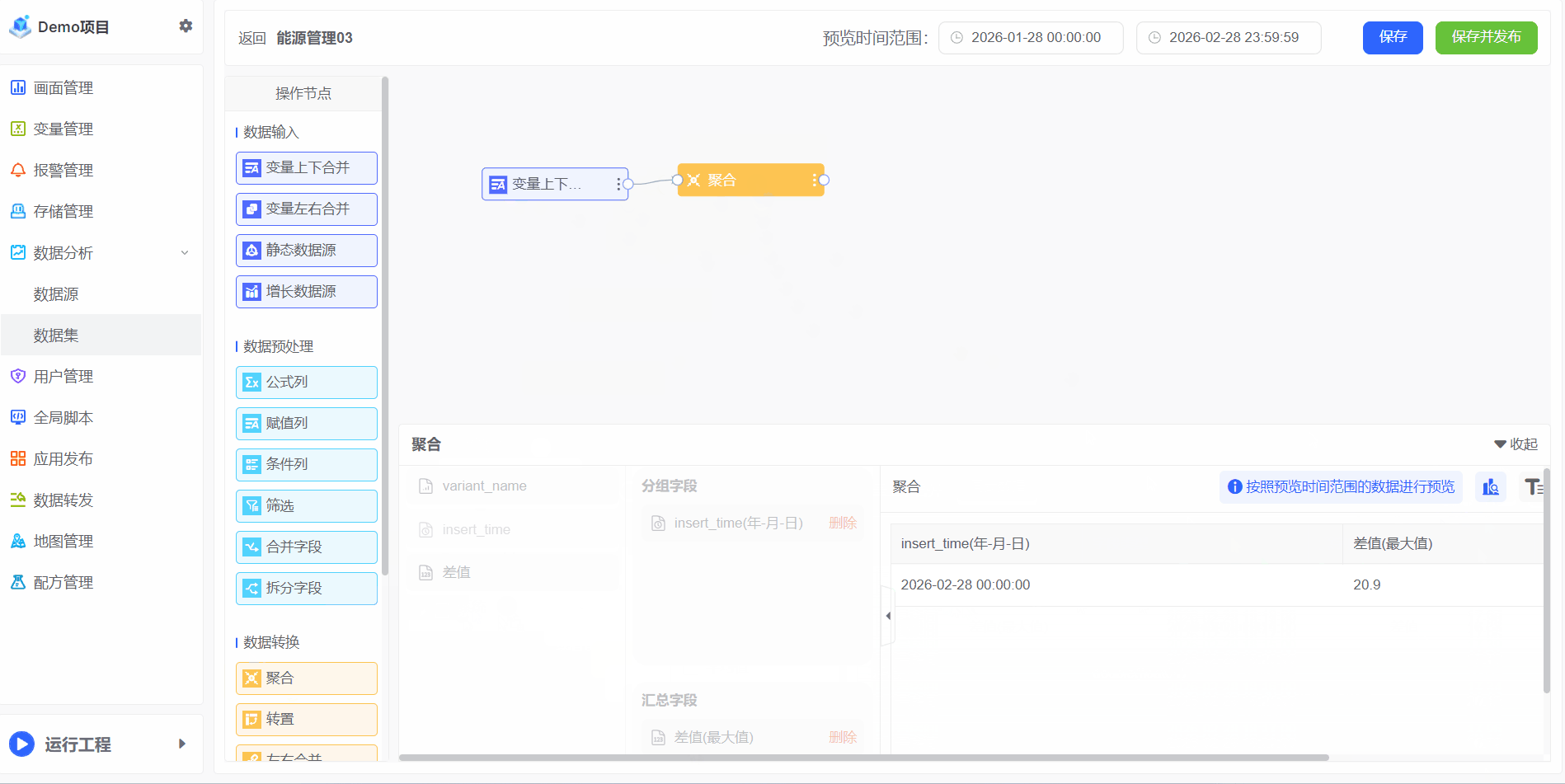
聚合
聚合对大量原始数据进行汇总与计算的过程,旨在通过数学或统计运算(如求和、平均值、最大值、最小值、计数等),提炼出数据的整体趋势、分布特征或关键模式。其核心目标是从复杂、细粒度的数据中提取高价值的洞察,为业务决策提供可靠依据
数值型数据: 可按指定维度(如日期、区域、产品类别等)执行多种聚合运算,包括但不限于: 求和、平均值、最大值、最小值、差值(如当日最高与最低值之差)、起始值、结束值 等,以全面刻画数据的变化规律
文本型(分类)数据: 主要支持 计数类聚合,例如:
非空值计数(Count):统计出现次数;
唯一值计数(Distinct Count):统计不重复的类别数量
示例:电能变量是总电量,每小时存储一次,电能变量的数值是永远根据实际电量消耗递增的。
1、若需计算每月总耗电量,可通过聚合操作实现:
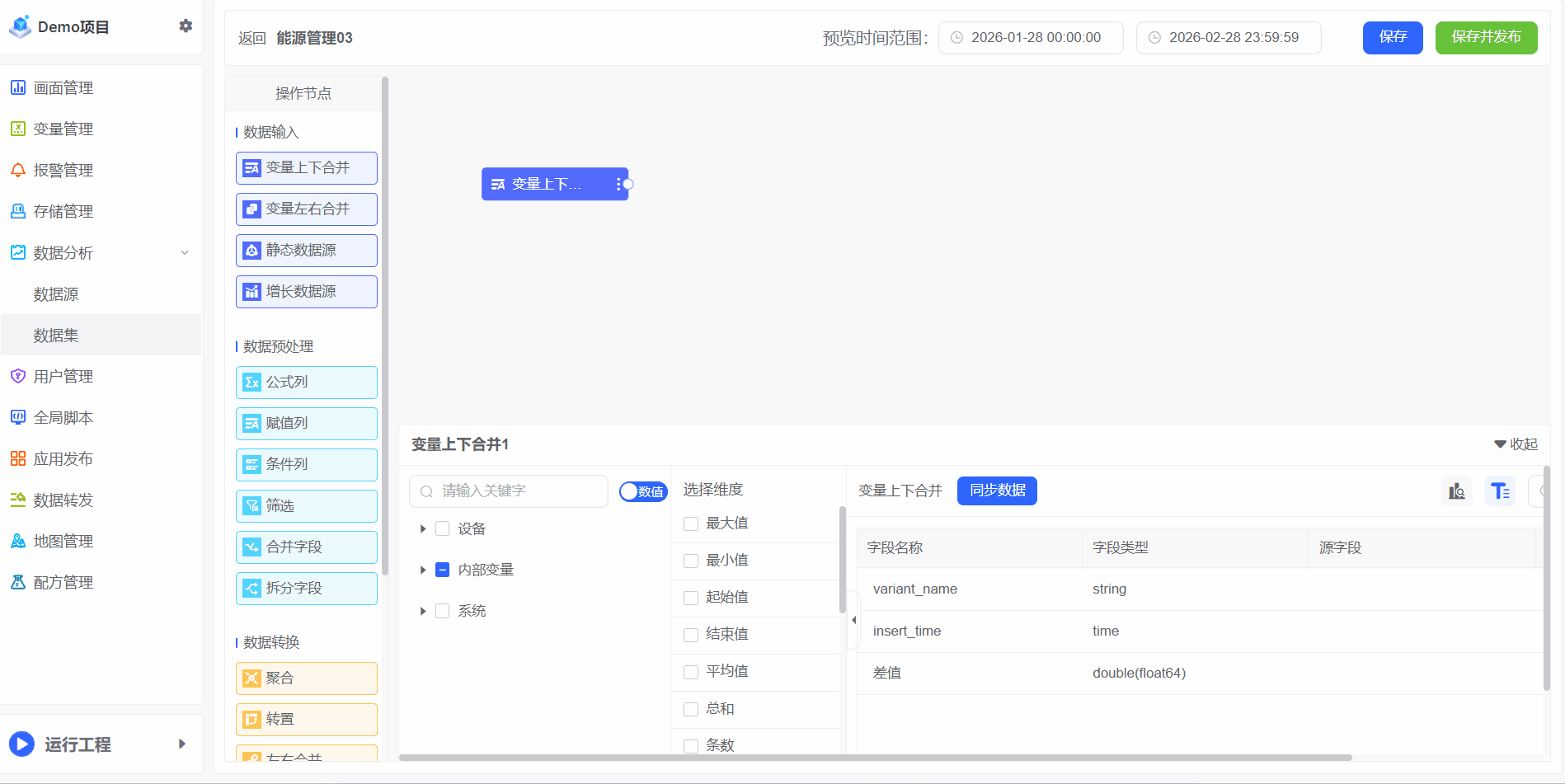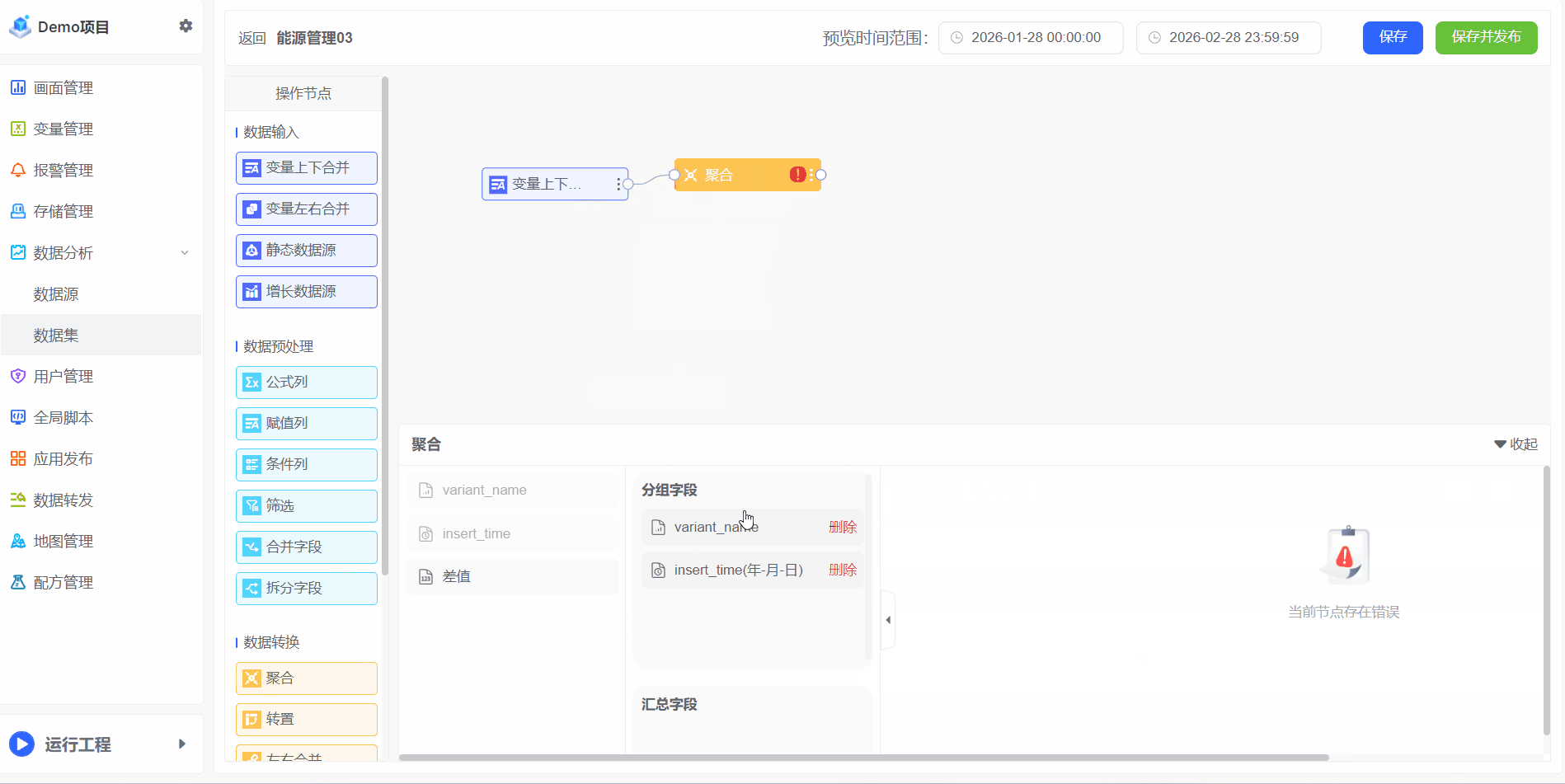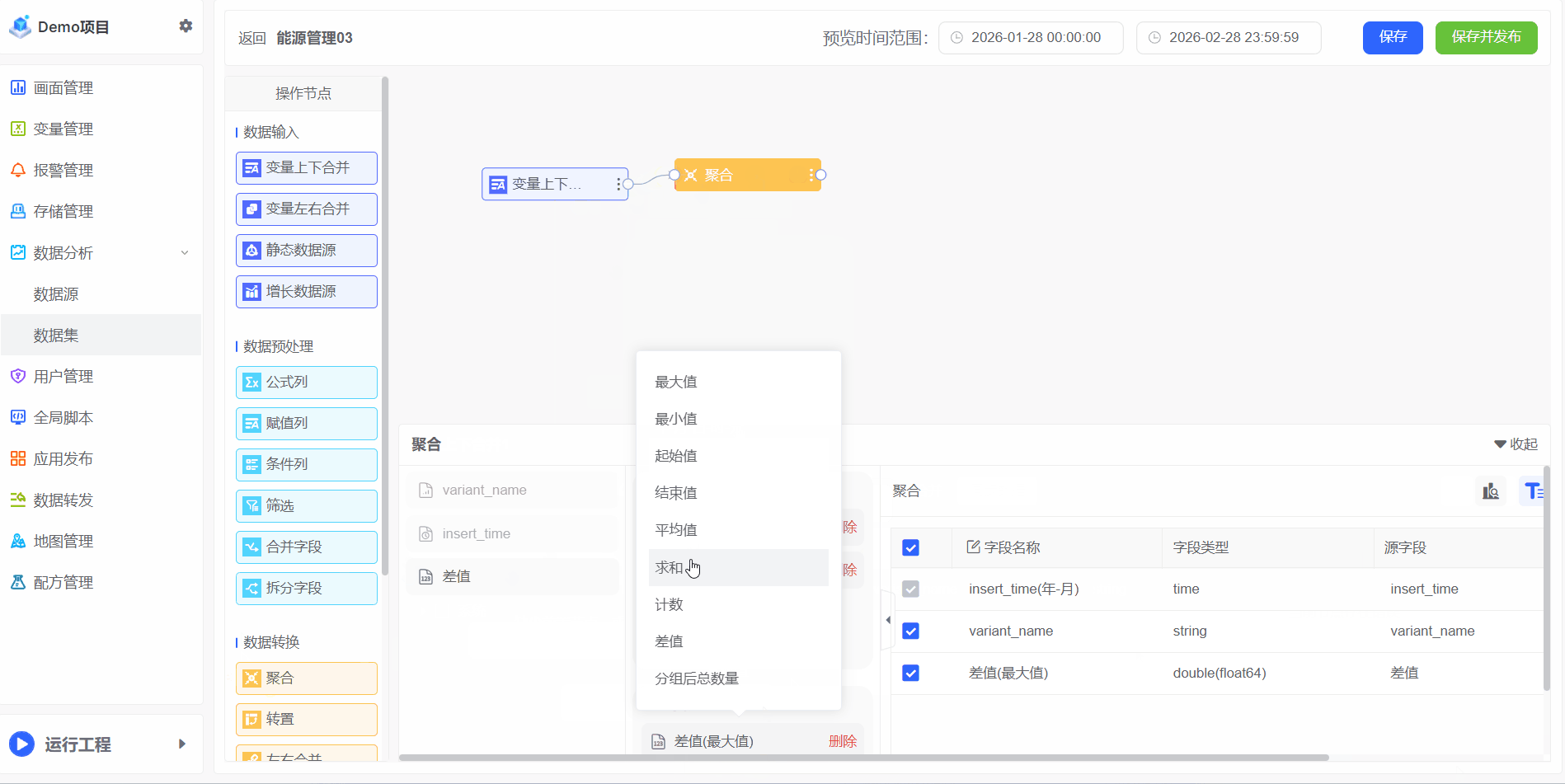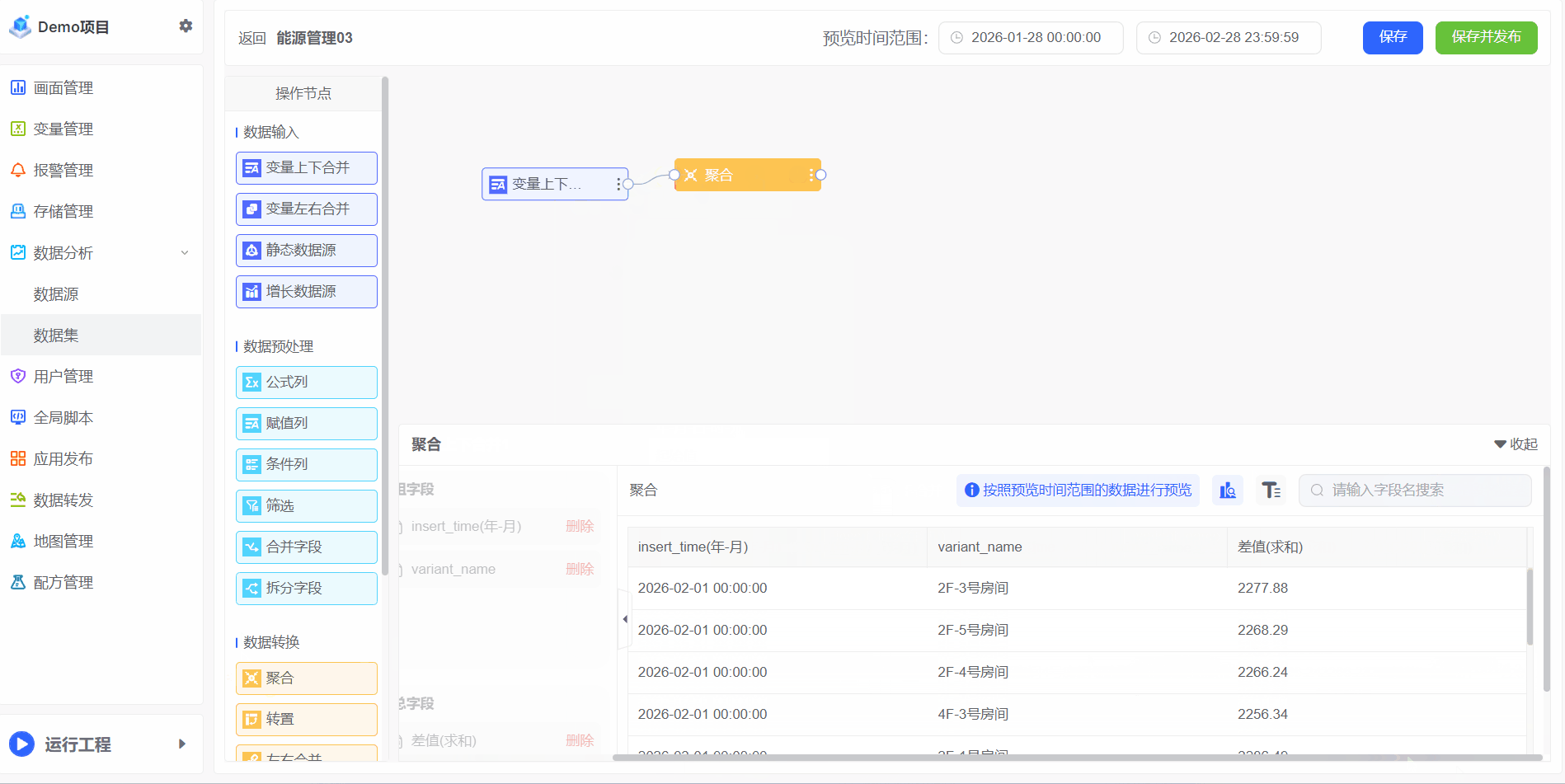
2、如需计算所有房间的数据,可通过聚合操作实现:
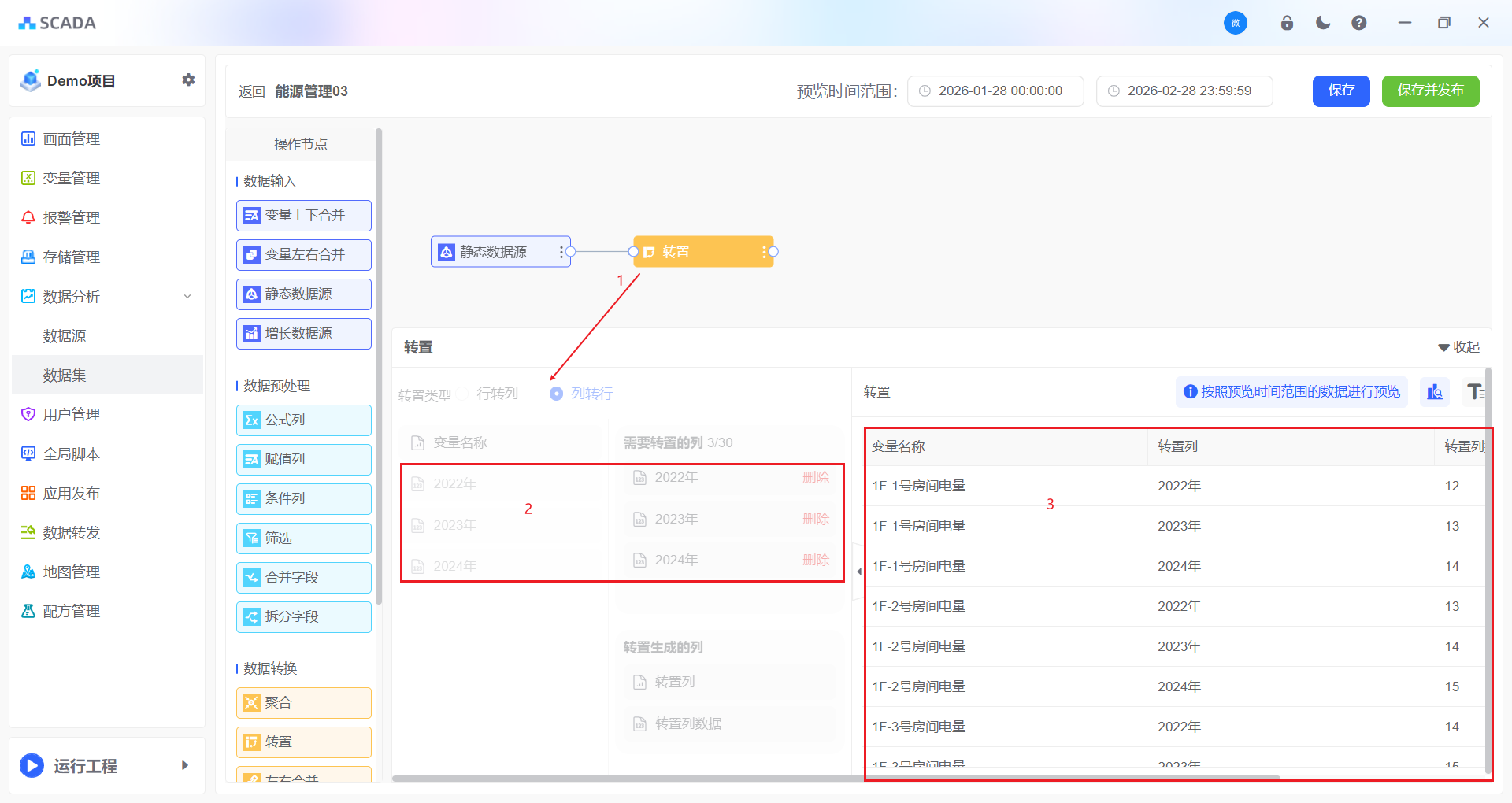
转置
转置 是将数据表中的行和列进行互换的操作。这种操作在数据处理和分析中非常有用,因为它可以改变数据的布局,使得数据的阅读和理解更加符合特定的分析需求。
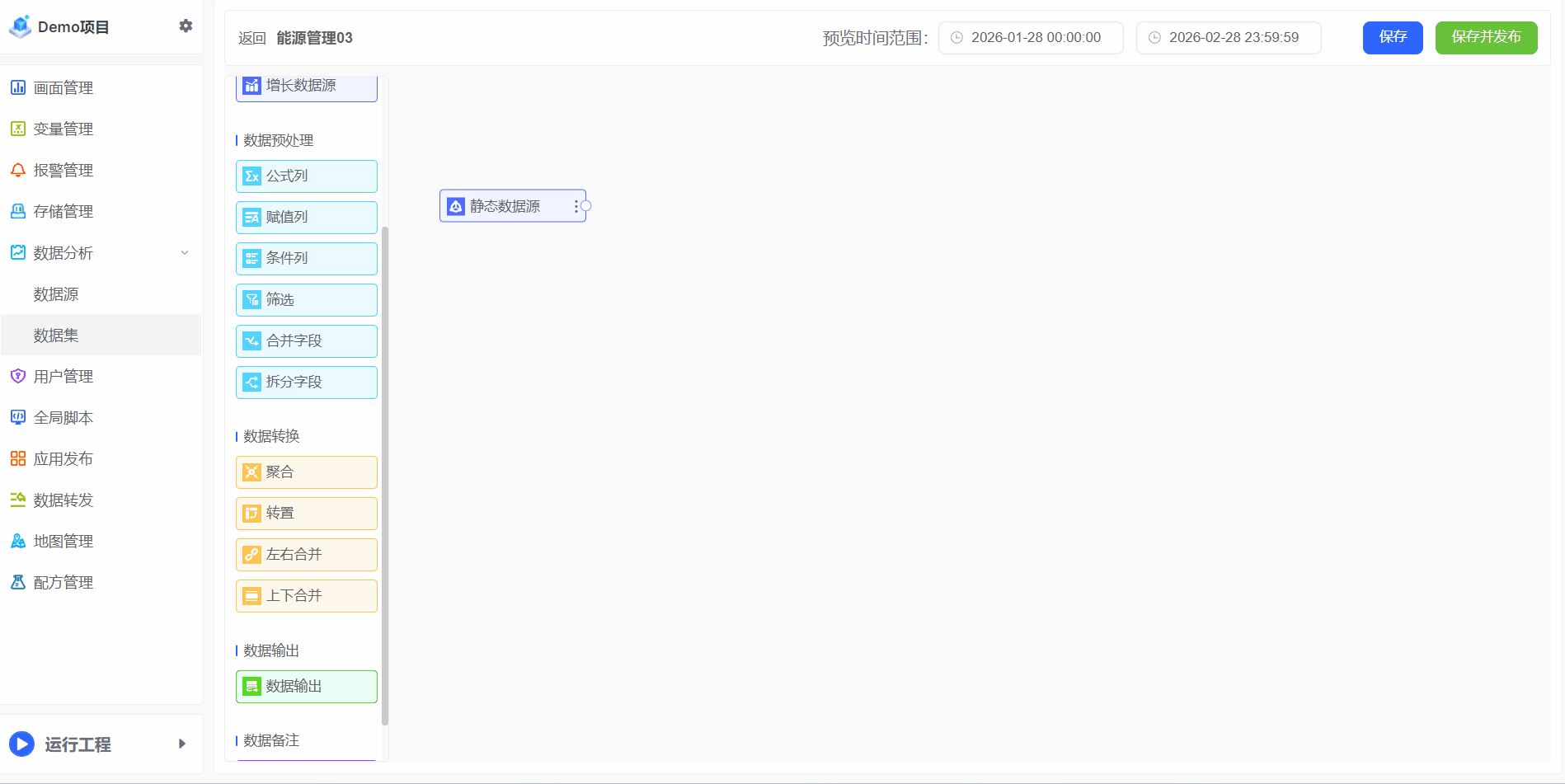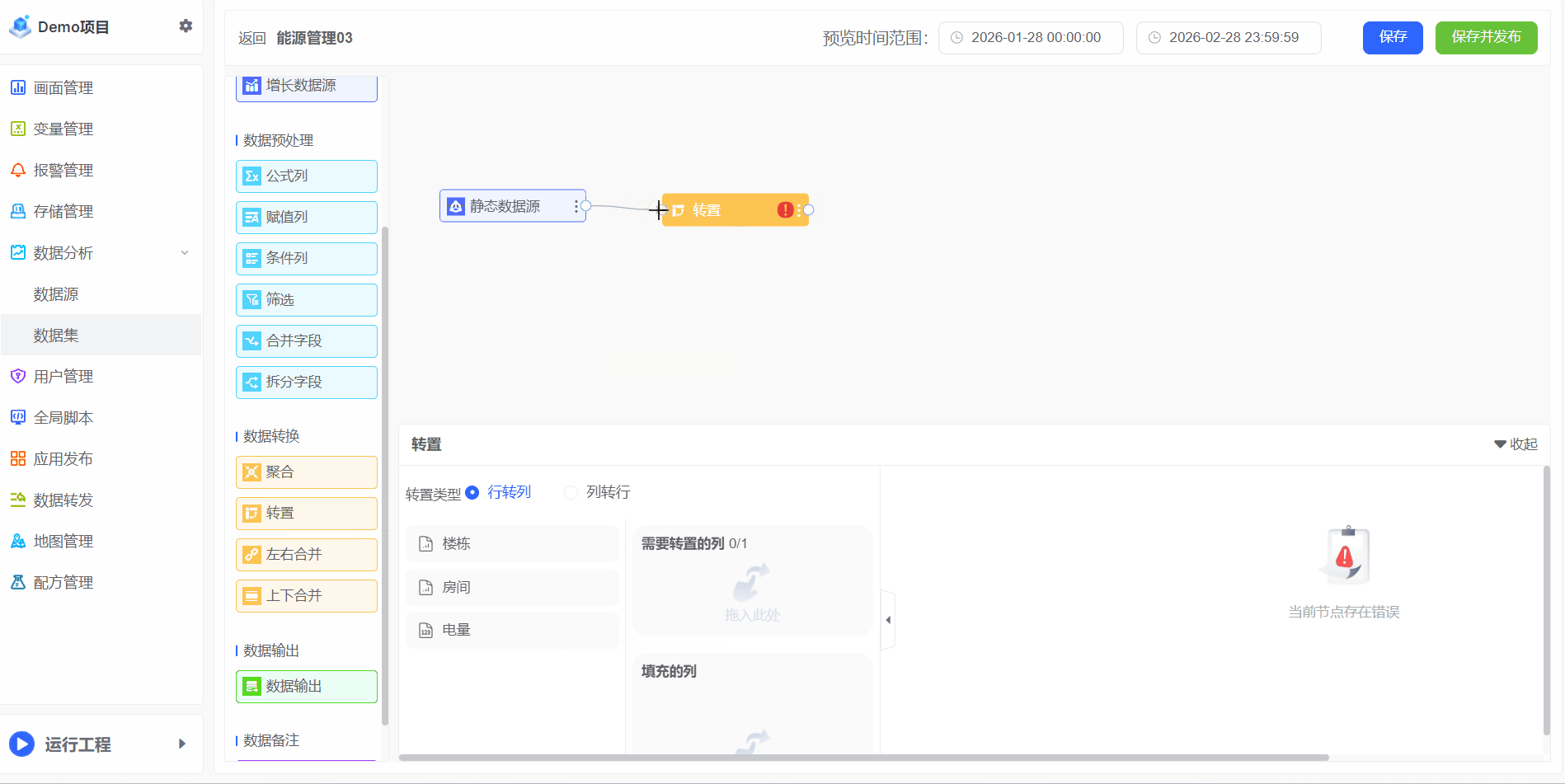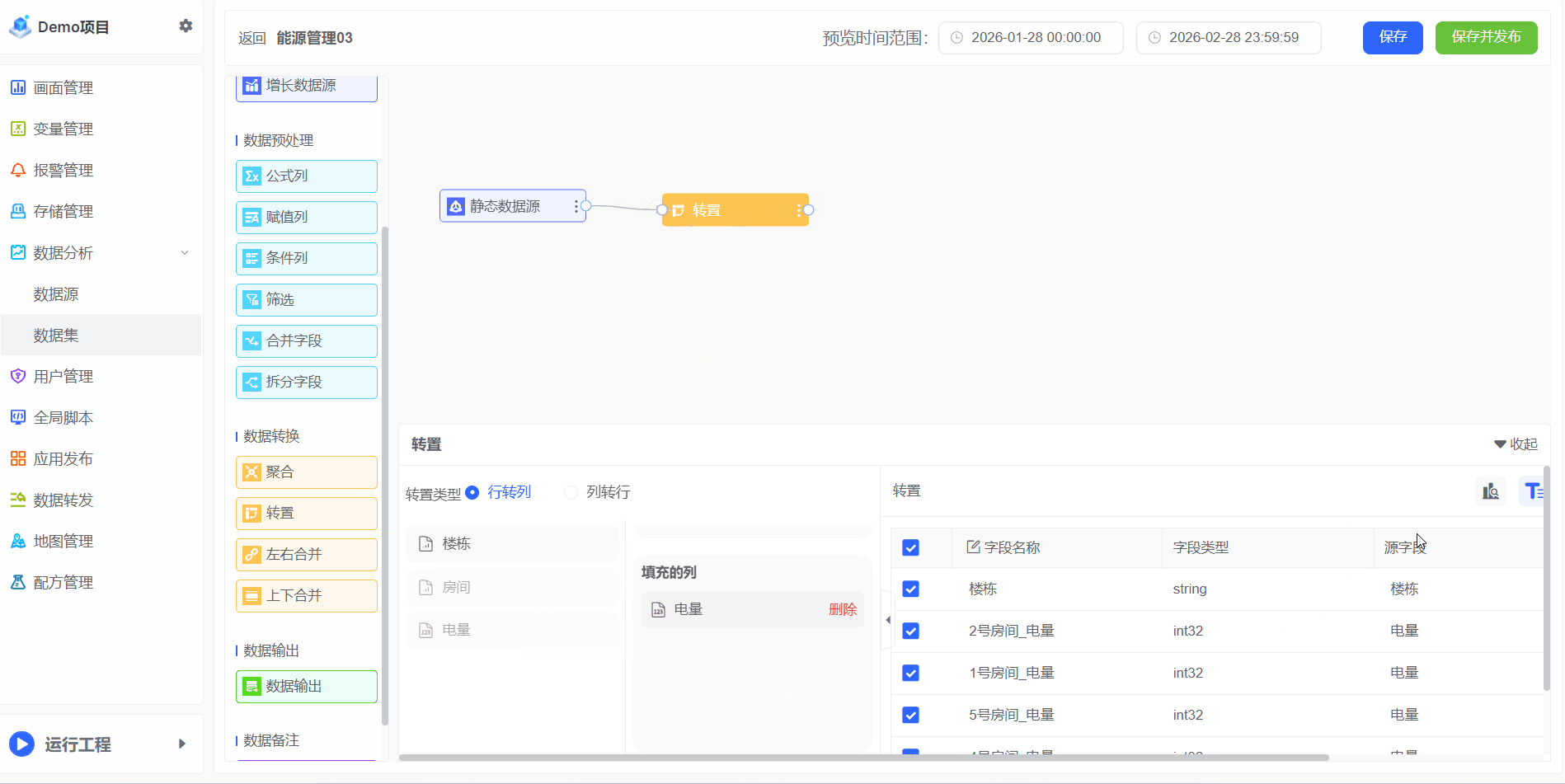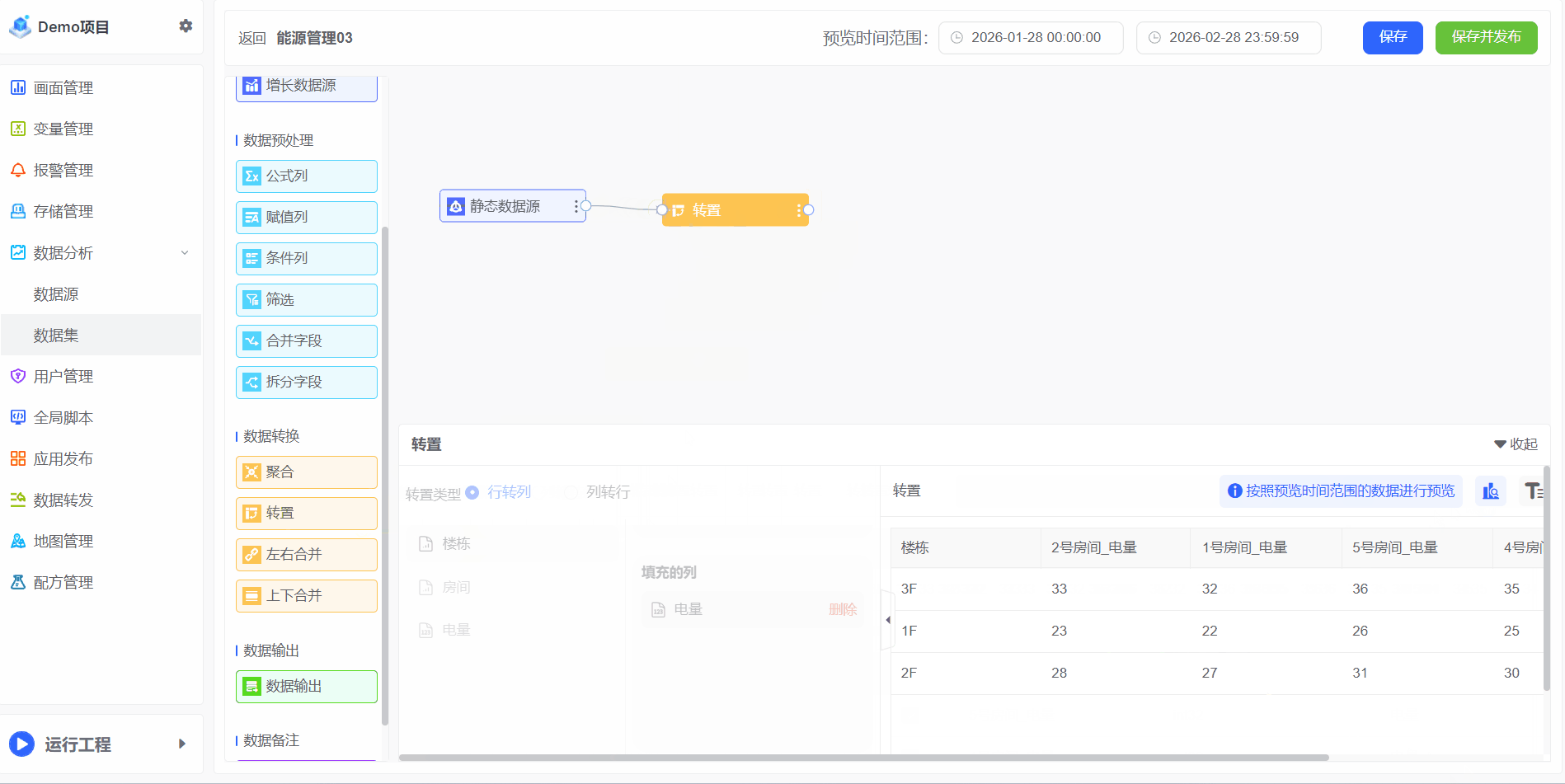
行转列
- 将数据展示为更直观的数据

- 操作步骤
列转行
- 将数据转换为更易于分析的数据
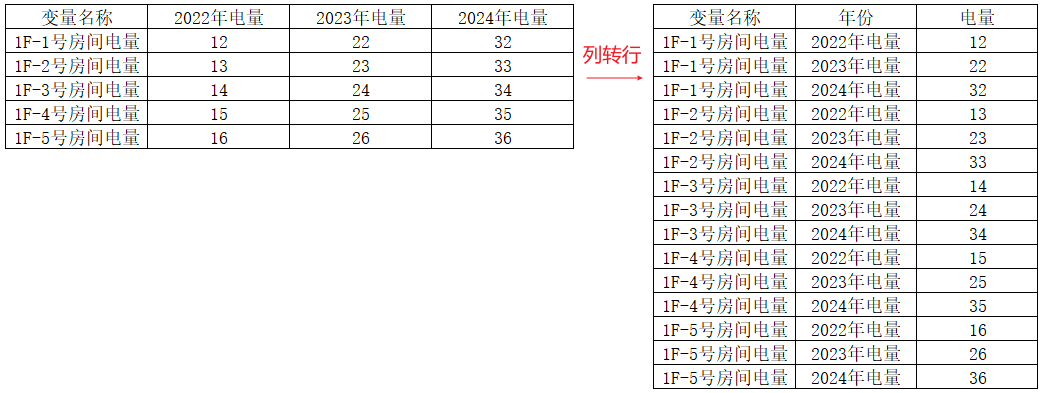
- 操作步骤
左右合并
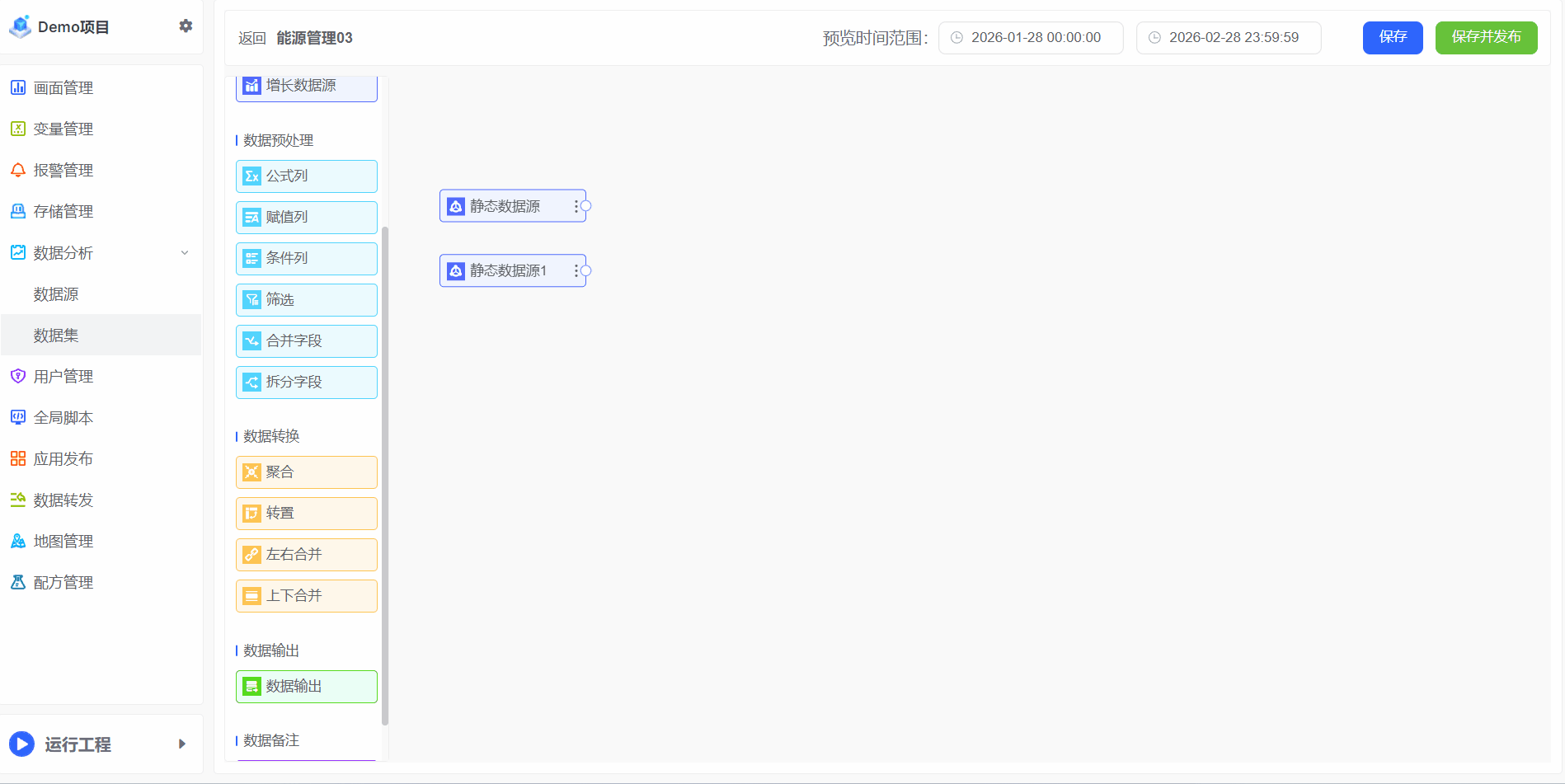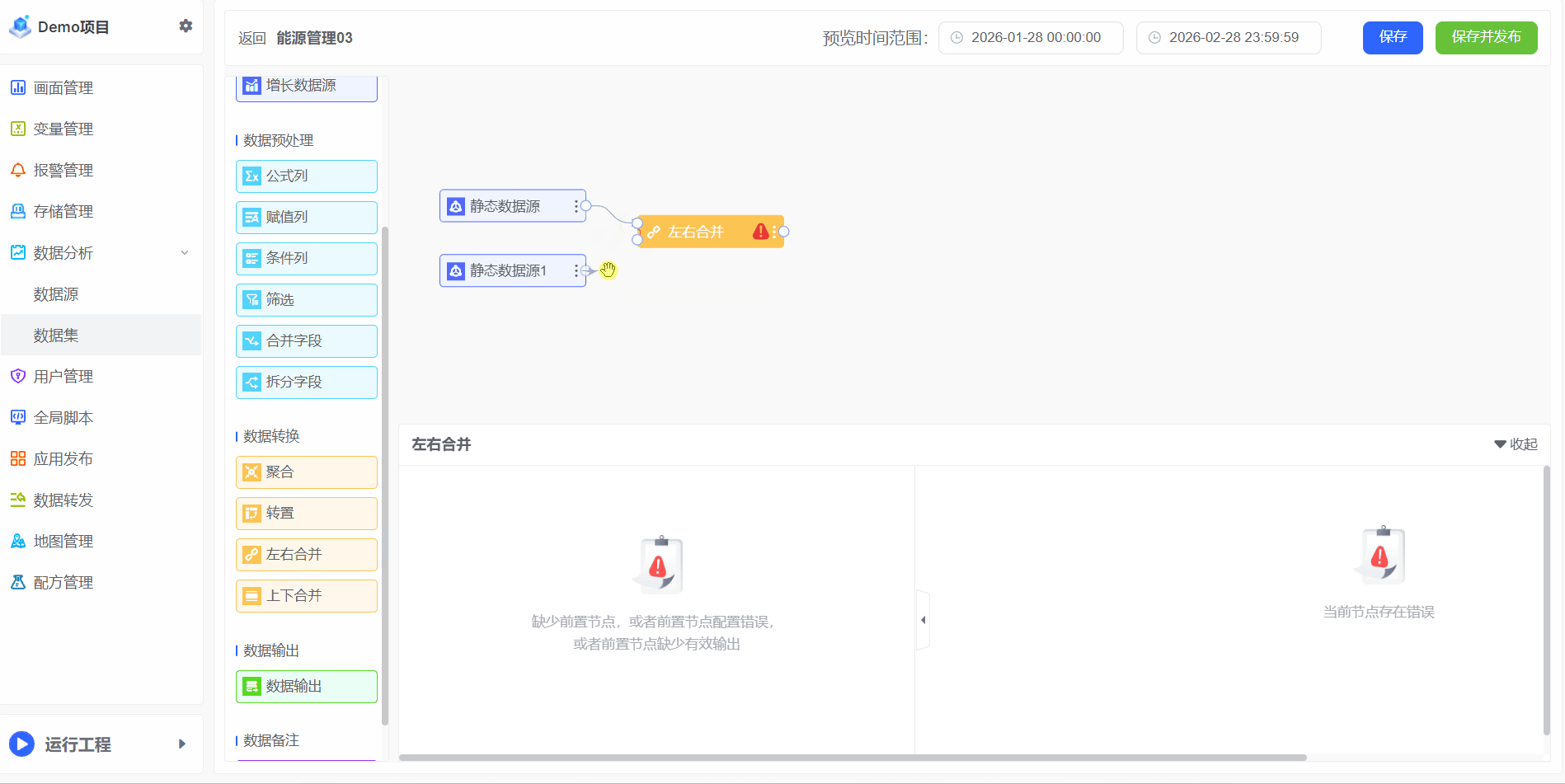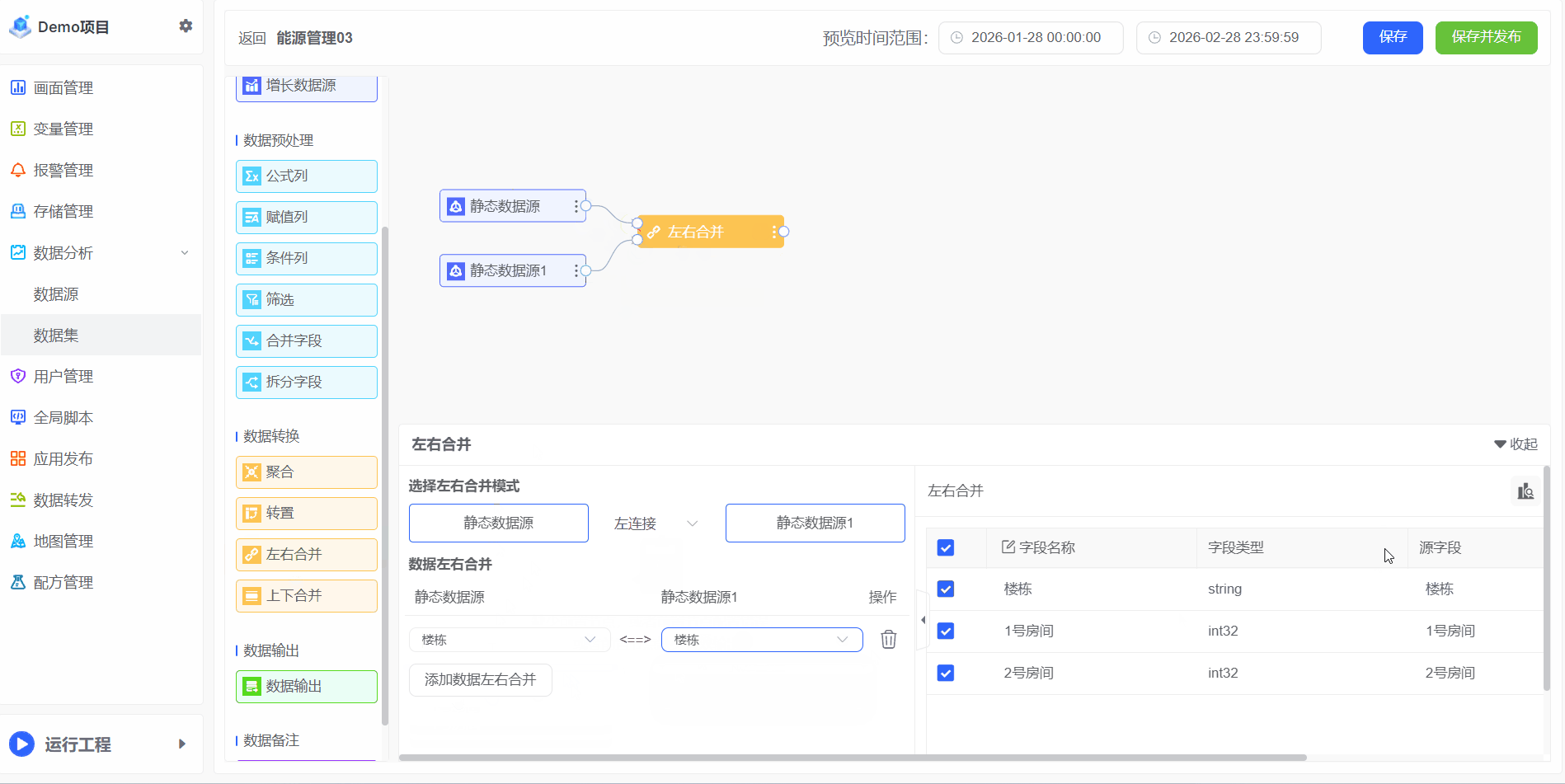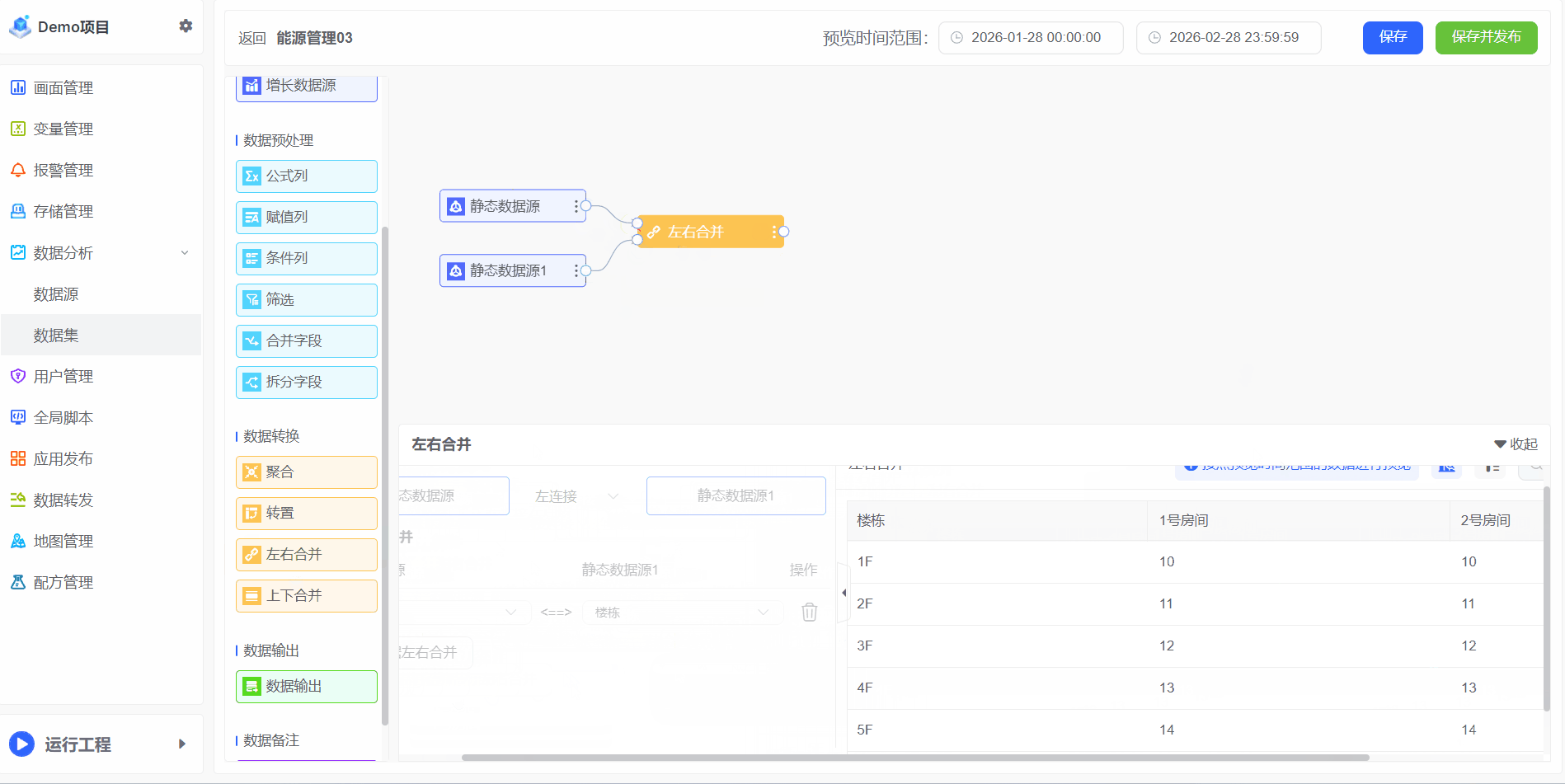
“关联”是将数据源按照相同的字段进行合并,以建立不同数据表之间的关系。这种关系使得数据能够在不同表之间进行有效的连接和导航,从而支持复杂的数据分析和报表生成
- 例如A有1F~5F分别1号房间的电能消耗,表B有4F~6F分别2号房间的电能消耗,合并为一张表

名词解释
| 名词 | 说明 |
|---|---|
| 左链接 | 以表A为基准 |
| 右链接 | 以表B为基准 |
| 内链接 | 对表A、B取交集 |
| 全链接 | 对表A、B取并集 |
- 将两张表左右合并为同一张表,操作步骤如下:
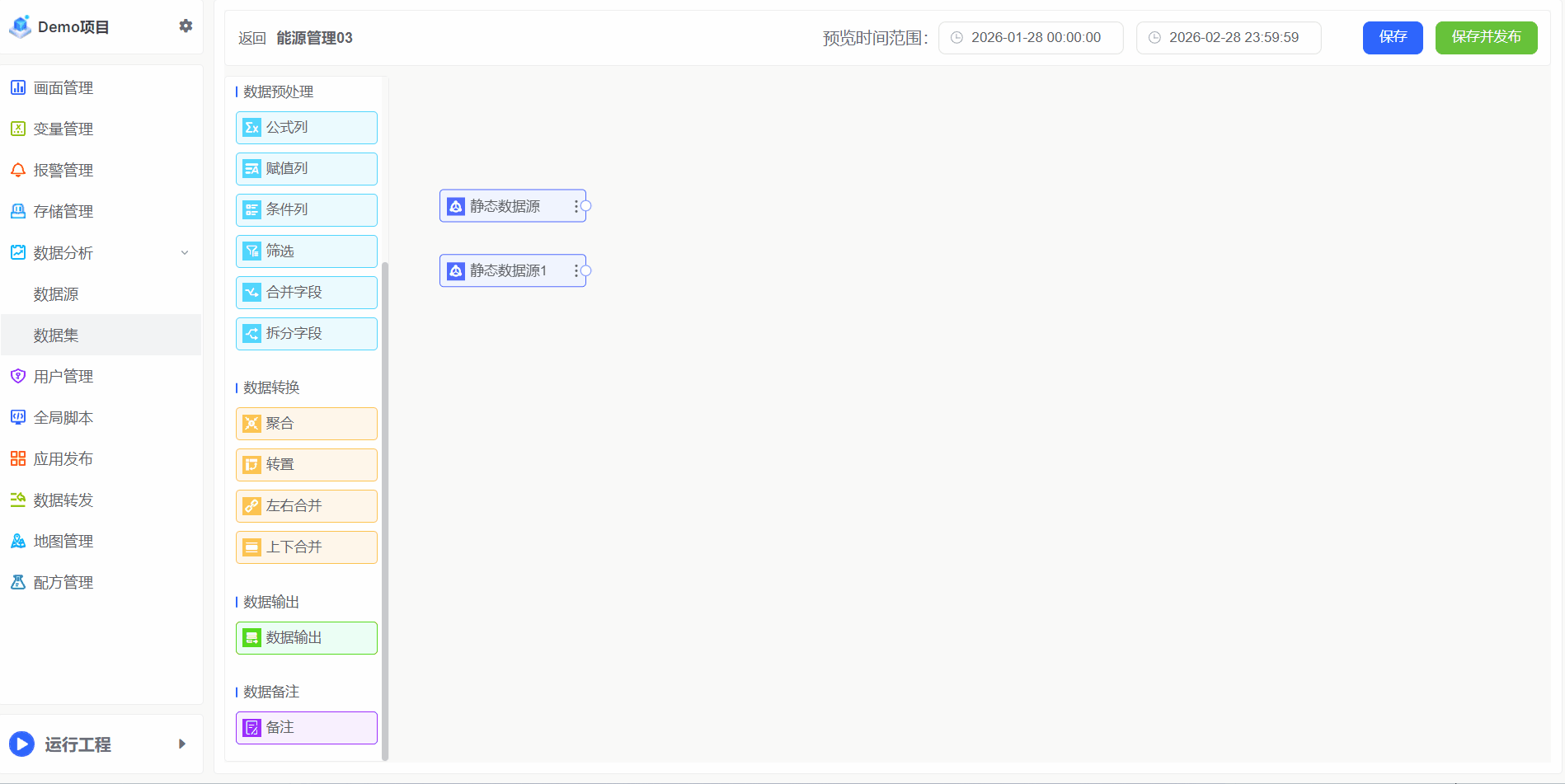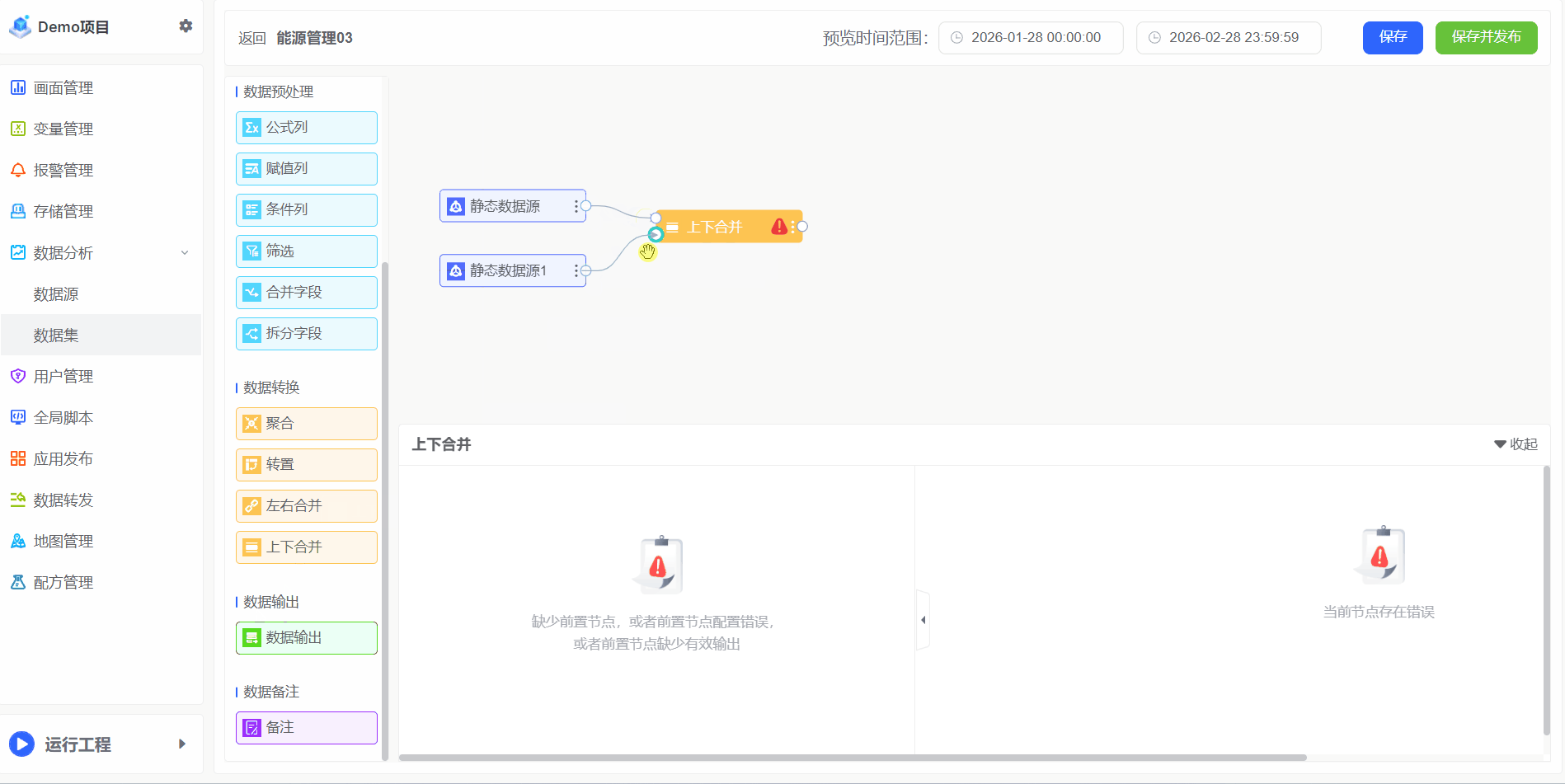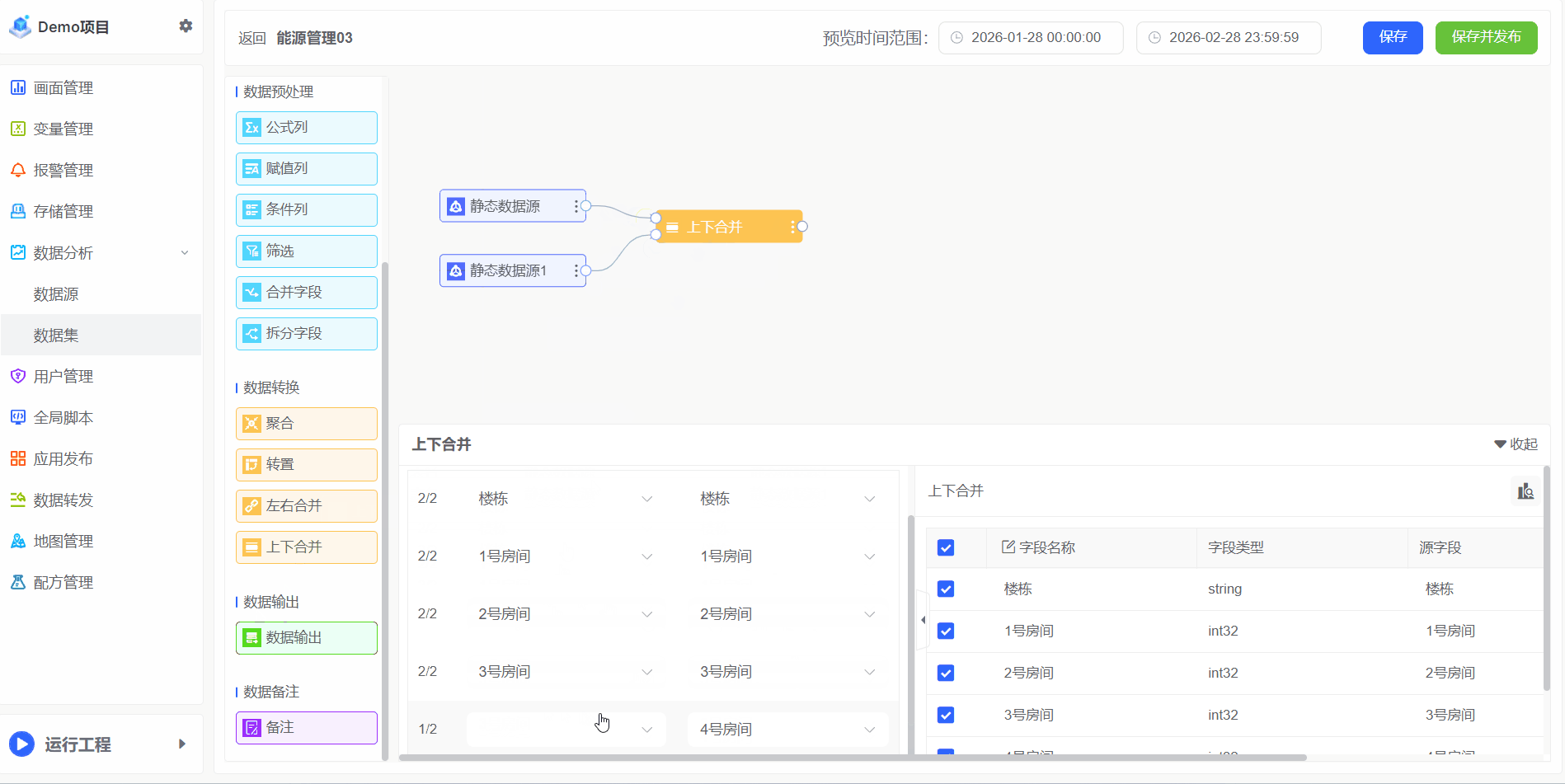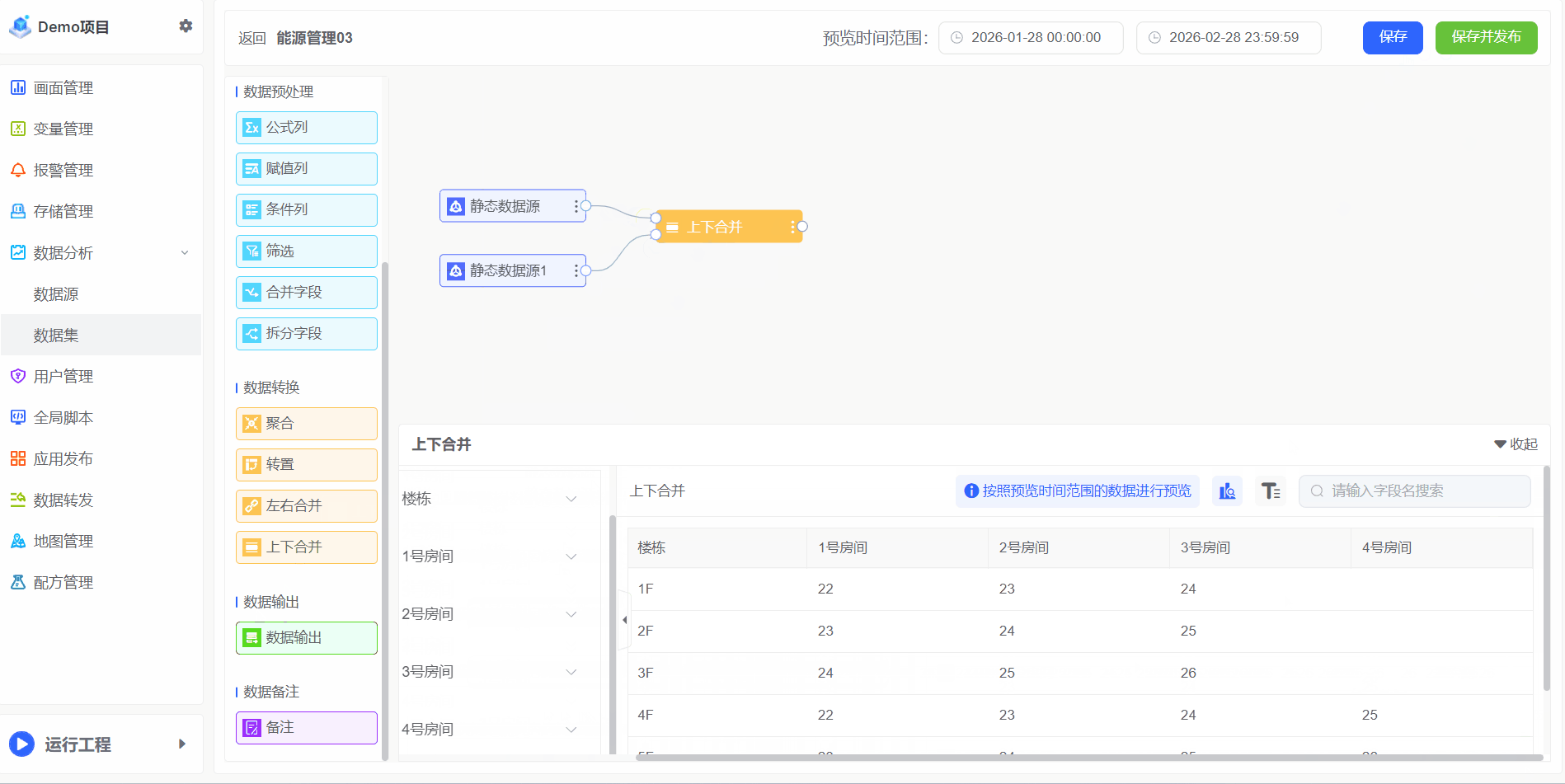
上下合并
"合并"是将来自不同数据源的数据集合并成一个统一的数据集,以便进行分析和可视化。这一过程对于创建全面的报表和仪表板至关重要,因为它可以将分散在不同数据库、文件或应用中的信息整合起来,以获得更完整的业务洞察
例如表A有1F~3F分别3个房间的电能消耗,表B有4F~6F分别4个房间的电能消耗,合并为一张表
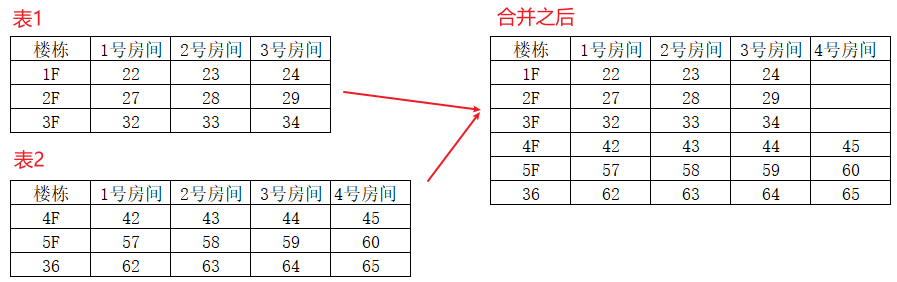
将两张表上下合并为同一张表,操作步骤如下:
数据输出
数据集的最后一个节点,将数据关联到该节点,然后点发布,后台任务将从数据库拉出全部数据组装并生成一张新表。